
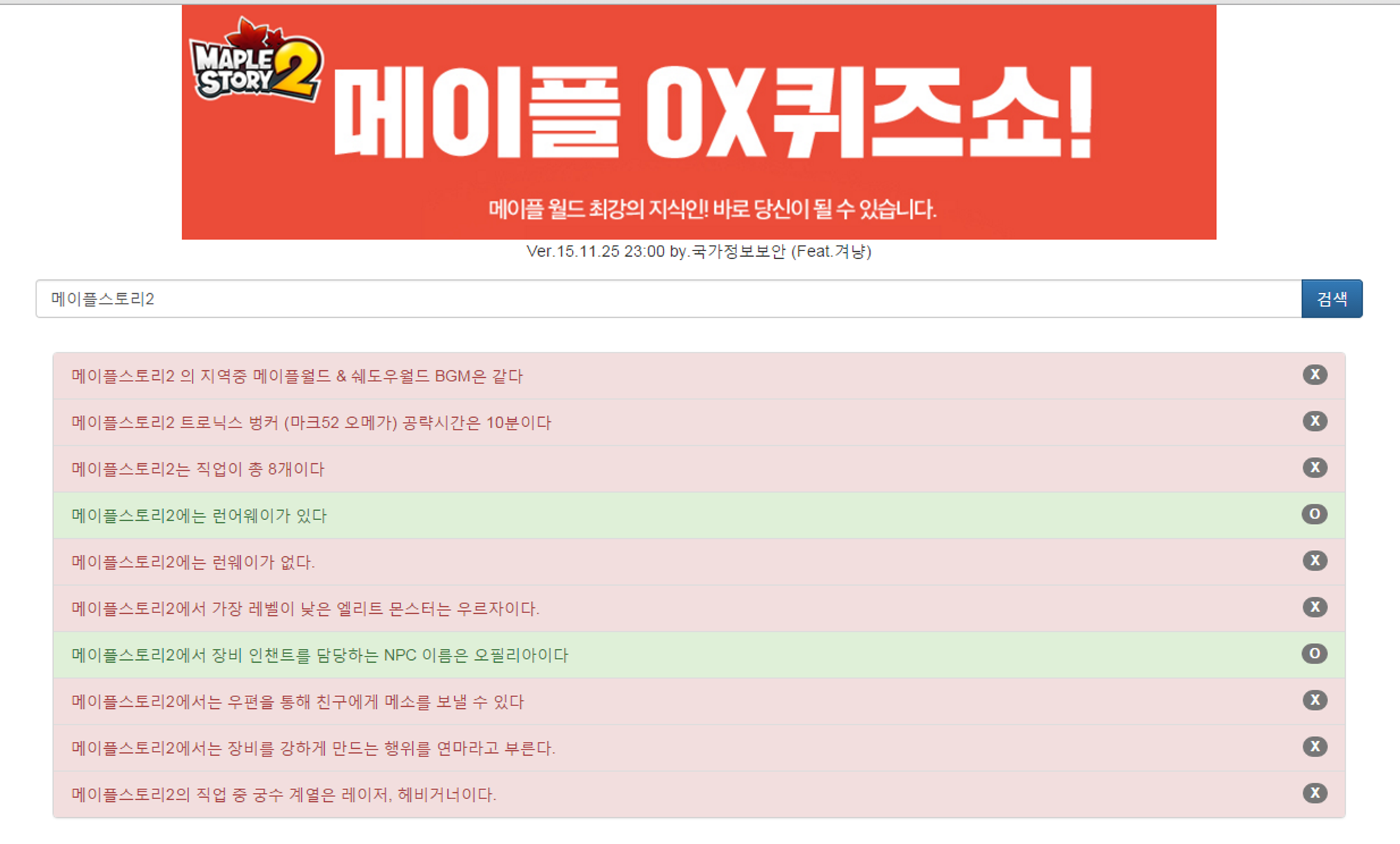
메이플스토리가 흥했던 2017년도에 “메이플스토리2 OX 퀴즈” 사이트가 있었다. 메이플스토리2에는 “OX 퀴즈” 시스템이 있었는데, 이 퀴즈에서 정답을 맞추면 특정한 보상이 나왔다. “메이플스토리2 OX퀴즈” 사이트는 이 퀴즈에 나오는 문제와 정답을 모아둔 곳이다. 그 당시 “국가정보보안”님이 운영을 했었다. 지금은 접속되지 않지만 아마 기억하는 사람이 있을것이다.
사이트의 특성상 “검색”이 주요 기능이 된다. 수많은 문제 중에서 내 문제를 풀어야 하기 때문이다. 그렇기에 검색시간이 사용자 경험의 거의 전부이다. 이 사이트는 처음엔 텍스트 검색 (like %검색어%) 으로 데이터를 검색했다. 초반에는 전혀 문제가 없었다. 하지만 데이터가 늘어남에 따라 검색속도 또한 엄청 느려졌다. 17년 3월 기준으로 3만개의 문서가 있었는데, 퀴즈 시간만 되면 검색에 수십초가 걸렸었다.
https://archivebox.esukmean.com/archive/1651939547.808099/index.html
해당 사이트는 MySQL을 사용했었는데, 이런저런 여건상 (MySQL의 버전, Full Text에서 한글은 지원안함, 최소 글자수의 존재, 검색해서 나오는 문서도 얼마 없음) DB 내의 Boolean Full Text 검색기능을 사용할 수 없었다. DB내의 기능으로 못하고, 제한된 환경에서 직접 검색 시스템을 만들어야 했다. 쉬운 문제가 아니다 보니 “고쳐야지… 고쳐야지” 하면서 미루고 미뤄졌었다. 그러다가 원래 개발자에게 문제가 생겨서 나한테 까지 오게 됐었다.
그래서 직접 Full-Text Search 검색시스템을 만들게 됐다. (사실 검색시스템이라고 하기도 뭣하다) 많은 문서들 사이에서 내 키워드가 빠르게 검색되게 하기 위해서는, 최대한 인덱스를 타도록 해야한다. 기존 %—% 를 통한 패턴 매칭은 데이터 전체를 읽어봐야한다. 필연적으로 데이터가 많아지면 느려질 수 밖에 없다. 하지만 검색시 인덱스를 타게 하면 순식간에 원하는 데이터만 필터링 할 수 있다.
일반적으로 DB에서 인덱스는 “데이터”를 향해 건다. 그리고 해당 인덱스로 검색을 한다. 이때의 인덱스는 “데이터 내의 각각의 단어” 같이 세밀하게 걸리지 않는다. 우리가 원하는 검색단위는 “단어”인데, 인덱스는 “컬럼의 값”을 통으로 바라보기 때문에 바라는 대로 작동하지 않는다. 그러므로 우리가 원하는 형식(단위)로 따로 인덱스를 만들어 줘야 한다. 다시 말해서, “단어 단위”로 문장(컬럼의 데이터)을 분리하고 이것을 인덱스에 태워야 한다. 이것은 비단 문서에만 적용되는것이 아니라, 통으로 된 데이터에서 특정 단위로 검색하고자 할 때 공통적으로 적용되는 부분이다.
검색시스템에서 이런 인덱스 구조를 “역인덱스”라고 한다. 기존에는 데이터에 인덱스를 거는것을 기본으로 했다. 그러나 여기선 역으로 “검색될 키워드”를 인덱스화 한다. 검색될 키워드를 인덱스화 하고, 그것으로 문서를 찾는다. 방향이 다른것이다. 그래서 inverted index, 역 인덱스라고 한다. 구조 자체는 3개의 table만 있으면 된다. 1) 키워드 테이블, 2) 문서 테이블, 3) 1과 2를 연결해 주는(M:N) join 테이블만 있으면 된다.
키워드 테이블에는 검색할 키워드가 들어간다. “메이플스토리는 한국 게임이다” 라는 문장이 있을때, “메이플” “메이플스토리”, “한국”, “게임” 이런식으로 사용자들이 검색할만 키워드가 들어간다. 주의할 점은, 이 테이블에 있는 데이터로만 검색이 가능하다는 점이다. 인덱스를 빠르고 정확하게 태우기 위해 키워드 자체를 인덱스로 건다. 만약 검색 시스템에서 2글자 부터 검색을 하게 한다면, 2글자 단위의 검색어 모두가 여기 들어와야 한다. 단어 단위로 검색되게 하려면 여기에 모든 단어가 들어와야 한다.
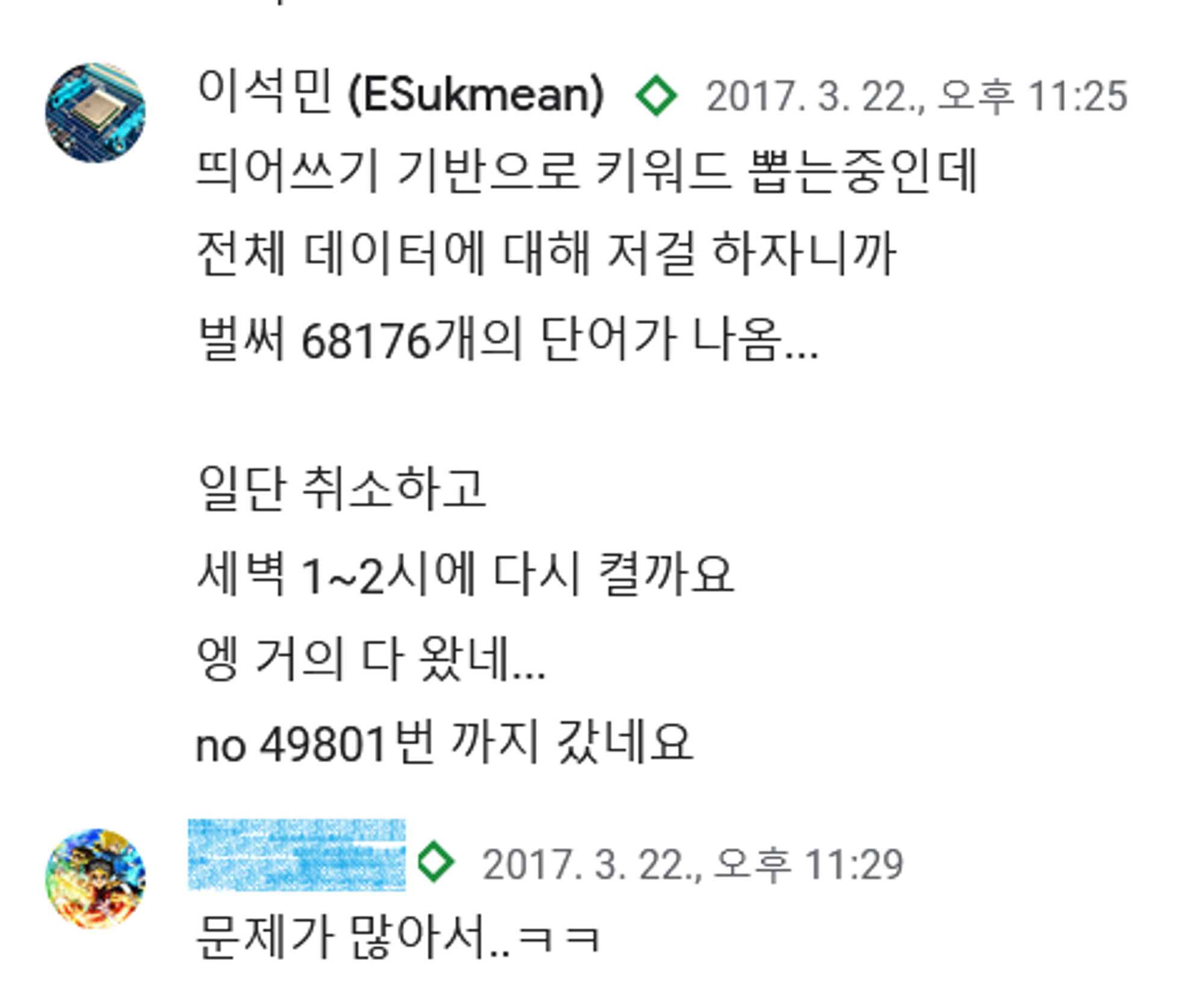
키워드 테이블을 만들기 위해 선행작업을 했었다.
문서 테이블은 일반적인 문서들이 모여있는 테이블이다. Join Table은 문서테이블-키워드테이블 을 엮어주는 기능을 한다. 문서가 M:N 구조를 가지기 때문에 이것을 묶기 위해 필요하다. 예를들어, “메이플”이라는 검색어에 3~4개의 문서가 연결될 수 있다. 이 3~4개의 문서는 “하루” 라는 단어에 묶일 수 있다. 이것을 이어주기 위해서 Join 테이블이 필요하다.
저거를 만들때 단어 단위로 짜르고, 다시 2-gram 단위로 인덱싱 했었다. 그리고 띄어쓰기 기준으로 1글자는 별도로 인덱싱 하도록 했다. 그렇게 해서 서비스 하니까 기존에 비해 엄청난 속도로 검색이 됐다. 사람이 없을때도 수초에서 10초 정도의 반응시간이 나왔는데, 직접 검색기능을 추가함으로서 FTTB가 0.03초로 줄었다.

불리안+2-gram 구조로 매우 단순해서 사실 시간이 걸릴것도 없다.
사실 이것을 검색시스템이라고 부르기도 뭣하다. 특히 이 경우에는 질의하고자 하는것이 어떤 추상적인것이 아니다. 문제 자체를 바로 검색하기 때문에 매칭만 해주면 된다. 그렇기 때문에 사실상 검색엔진이라기 보다 매칭 시스템이라고 부르는게 더 합당하다. 2-gram 검색시스템을 PHP와 MySQL을 이용해서 구현한것이기에 매칭 시스템 중에서도 매우 간단한 편에 속한다.
요즈음 DB에서는 이런 작업을 기본적으로 다 해준다. 이런 단순한 검색시스템에서 자신이 튜닝하고 싶은 부분이 있는게 아니라면 DB에서 제공하는 기능을 사용하는게 편하다. 그러나 과거에는 이것을 직접 구현했어야 했다. (한국어 처리가 지원되지 않아서 직접 구현할 필요가 많았다.) 불현듯 과거에 만들었던 기억이 나서 글로 남겨본다.



답글 남기기