리눅스에서 TUN 인터페이스를 이용해서 이전에 썻던 Mutli-Path 오버레이 네트워크를 만들고 있다. 현재는 TUN 제어 자체는 어떻게 됐는데, UDP 소켓을 관리하고 연결 정보를 처리하는데 조금 어려움이 있다. 연결 관리 구조체 하나를 상위의 전체 관리 모듈과 본인 스스로에게서 접근하려다 보니 소유권이 발목을 잡는다. 생각해둔 방법이 없진 않은데, 아무래도 코드가 더러워지는것 같아서 꺼려진다.
각설하고, 개발간 초보 TUN 개발자가 볼만한 글이 없어서 시간이 불필요하게 많이 소모됐다. 이정도 내용은 어디 있을것 같은데… 싶은것도 별로 없더라. 그래서 초보자가 마딱드릴만한 내용 몇개를 적어보고자 한다.
read() 콜 발생시 패킷 단위로 데이터가 수신됨
read() 한번에 패킷 하나만이 수신된다. 그러므로, 여러 패킷이 들어온다는 걱정은 할 필요 없다. 또한, 손상된 패킷이 들어와도 해당 패킷만 drop (discard) 하고 넘어가면 된다. 크기 부분이 다르다 한들 (IP length != read_len) 그냥 넘어가면 된다.
버퍼의 크기는 MTU와 같거나 커야한다. read()콜 시 패킷 하나가 그대로 수신되므로, 버퍼가 작다면 뒤의 내용이 짤릴 수 있다. ifconfig, ip addr 등으로 사용자가 MTU를 바꿀 수도 있으니 안전하게 버퍼 크기를 두자.
처음 패킷을 읽을때 걱정한 것이 TUN 장치를 read()로 읽을때 데이터가 중간에 끊겨서 들어오면 어떻게 하냐? 라는 걱정을 가졌다. 예를 들어 버퍼가 4000B인 상태에서 ᅟ1500B (IPv4 20B + Payload 1480B) 데이터가 들어온다고 하자. 만약 TUN 장치쪽에 이러한 패킷이 3개 이상 있고, 이것이 read() 콜 한번에 다 들어온다면 버퍼 관리를 해야할 것이다.
또 다른 걱정거리는, 패킷의 길이를 전적으로 패킷내 정보에만 의존해야 한다는 점이었다. 악의적인 프로그램이 100B 짜리 패킷을 1500B라고 속여서 보낸다면 이후의 버퍼가 전부 1400B씩 위치가 밀려서 정상적인 패킷 처리가 불가능 할 것이다. 그러나 read() 한번에 하나의 패킷만 들어오기 때문에 위의 걱정을 없엘 수 있다.
read() 콜은 패킷 하나를 읽는다. write()도 마찬가지로 하나의 패킷을 쓰는것을 의미한다. write()에 여러개의 패킷을 넣으면 동작하지 않을 수 있으며, 의미적으로도 맞지 않다.
필자는 Offload를 켜지 않은 않을때는 Jumbo Frame을 고려해서 9K를 버퍼 크기로 설정하였다.
중요한건, 버퍼 크기가 MTU 보다 적으면 데이터가 짤린다는 것이다.
Offload와 같은 옵션을 켜도, 무조건 1개의 패킷만 들어온다.
GRO로 패킷이 뭉쳐 들어온다 해도, 1개의 패킷만 읽힌다. 그러므로 우리는 무조건 read() 한번에 하나의 패킷만 들어온다고 생각하면 된다.
IFF_NO_PI 옵션
인터넷 글을 보면 전부 IFF_NO_PI 옵션을 켜라고 한다. 이 옵션은 첫 4바이트에 패킷의 정보 (Packet Information) 을 출력한다. 여기서 나오는 4바이트는 tun_pi 라는 구조체를 바로 바이트로 뽑아낸 값이 된다. https://github.com/torvalds/linux/blob/master/include/uapi/linux/if_tun.h#L98C1-L102C1
Protocol은 EtherType을 의미하는데, https://github.com/torvalds/linux/blob/master/include/uapi/linux/if_ether.h#L52 에서 Hex 코드를 확인할 수 있다. flag는 왠만해서 0x0000이다. 가능한 설정들을 ioctl(tunsetiff) 로 집어넣어봤는데 전부 0으로 나왔다. 검색해 보니 거의 reserved 수준이고, 쓰이지 않는것 같다.
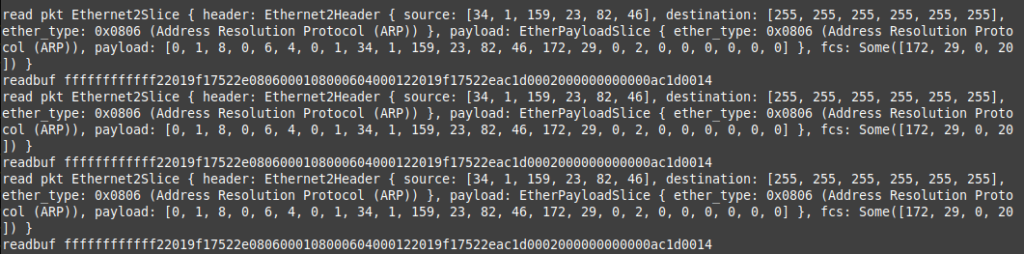
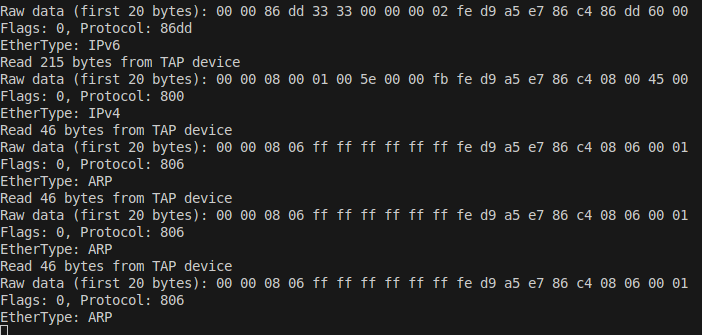
귀찮은 점은 IFF_NO_PI를 적용하지 않으면(unset) write() 시에도 tun_pi 구조체를 같이 써줘야 한다는 것이다. 즉, (4byte의 PI + 실제 패킷)을 써야한다. 프로토콜을 빠르게 판단할 수 있다는건 좋은데, 장치에 패킷을 쓸 때마다 정보를 넣어줘야 한다는 점에서 배보다 배꼽이 더 큰 상황인것 같다.
멀티 큐
TUN/TAP은 기본적으로 하나의 장치이다. 즉, 하나의 큐 만을 가지고 있다. 패킷 처리량이 많을 경우, 단일 큐에서 모든것을 감당하는것은 성능적ᅟ 상한치가 존재할 수 있다.
왠만한 경우에서 Single Queue로 인한 병목 발생 가능성은 거의 없다. 다만, 패킷기반 (Packet intensive) 시스템이라면 영향을 받을 순 있다.
TUN 장치에서는 확인하지 못했지만, 일반적인 NIC의 경우에서 여러개의 Queue를 가지면 패킷 처리를 여러 코어에서 나눠서 할 수 있다.
어쨋든 NIC에 들어온 패킷은 CPU에 의해서 처리된다. 이때 softirq가 개입하는데, 큐 하나당 1개의 코어를 사용한다. 만약 큐 수를 늘린다면 여러 코어를 사용해서 패킷들을 처리할 수 있다.
단순히 dup() 을 쓰거나, 동일한 fd를 여러 쓰래드에서 돌려쓰는 것은 TUN 장치가 제공하는 Multi-Queue가 아니다. 멀티 큐를 사용하고 싶다면 IFF_MULTI_QUEUE 플레그를 설정해야 한다 IFF_NO_PI와 함께 설정하면 되므로, 쉽게 설정할 수 있을것이다.
let tun_device = open_opts.open("/dev/net/tun")?;
let mut init_flags = match layer {
Layer::L2 => IFF_TAP,
Layer::L3 => IFF_TUN,
};
init_flags |= IFF_NO_PI;
// https://www.kernel.org/doc/html/v5.12/networking/tuntap.html#multiqueue-tuntap-interface
// From version 3.8, Linux supports multiqueue tuntap which can uses multiple file descriptors (queues) to parallelize packets sending or receiving.
// check if linux kernel version is 3.8+ and set IFF_MUTLI_QUEUE
if check_if_multiqueue_support() {
init_flags |= IFF_MULTI_QUEUE;
}
let mut req: ifreq = ifreq::new(name);
req.ifr_ifru.ifru_flags = init_flags as _;
unsafe { ioctls::tunsetiff(tun_device.as_raw_fd(), &req as *const _ as _) }.unwrap();IFF_MUTLI_QUEUE 설정을 끝낸 뒤에는 TUN/TAP 장치를 동일한 이름으로 필요한 큐 만큼 열어야 한다. 즉, 사실 멀티큐는 동일한 이름으로 TUN/TAP 장치를 여러개 만들어서 사용하는 방식이다. 위와 같은 TUN 장치 생성 코드를 필요한 큐 갯수 만큼 실행하자.
큐가 잘 등록됐는지는 tc -s qdisc show dev [TUN장치 이름] 을 실행하면 확인 할 수 있다. 잘 등록이 됐다면 최상단에 mq가 있고, 그 아래에 큐가 등록한 갯수만큼 있을것이다.
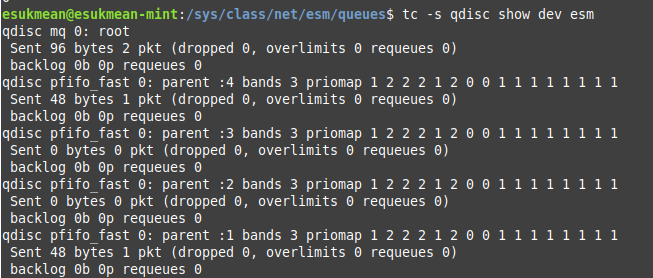
최상위의 qdisc: mq 아래에 4개의 일반 큐가 있다.
필요한 TUN/TAP 갯수 만큼 Open()을 했을것이기 때문에, 등록한 TUN/TAP 장치마다 각각의 fd가 나올 것이다. 해당 fd들을 읽고·쓰면 된다. 각 fd가 별개의 큐라고 생각하면 된다. 수평 확장을 위해, 각 fd는 다른 코어(쓰레드)에서 작동되도록 하는것이 좋다.
별다른 qdisc 설정이 없다면, 기본적으로 큐가 여러개일때 queue[hash(src addr + dst addr)] 로 큐가 선택된다. 그러므로 같은 목적지 주소에 대해서는 동일한 큐가 사용될 것이다. 대신에 같은 IP주소에 대해서는 동일한 큐가 나올것이므로, 큐 처리 단에서 패킷 최적화가 가능할 것이다.
리눅스 커널 문서에 따르면, multi-queue 지원은 커널 3.8+ 이상에서만 가능하다고 한다. 오래된 시스템에서는 지원하지 않을 수 있으므로 OS 버전을 체크한 뒤 기능을 가동하자. (특히 아직도 어딘가에서 동작하는 CentOS 6)
Offload (패킷 뭉치기)
Cloudflare에 따르면 64KB 바이트의 버퍼가 필요하다고 한다.
이론상 TCP의 최대 MSS인 64KB를 의미하는것으로 보인다.
결국 하나의 패킷 단위로 들어오는것이므로, 여건이 된다면 64KB의 페이로드를 꽉꽉 채워서 보낼것으로 추정할 수 있다. 그러므로, IP + TCP(UDP) MSS 만큼의 데이터가 필요할 것이다.
패킷마다 read() 콜이 발생한다면 시스템 콜 수가 많아서 성능이 느려질 수 있다. offload를 사용하면 한번의 read() 콜에서 여러개의 패킷을 뭉쳐서 처리할 수 있다. (MTU에 맞게 쪼개져야 할 패킷이 쪼개지지 않은채로 들어온다) 특히 패킷 수가 많은 시스템에서는 시스템 콜을 줄여서 최대 성능을 높일 수 있다.
Offload는 ioctl(tunsetoffload, 'T', 208)를 통해서 설정할 수 있다. (https://github.com/torvalds/linux/blob/master/include/uapi/linux/if_tun.h#L40) 설정 가능한 옵션은 TUN_F_CSUM, TUN_F_TSO4, TUN_F_TSO6, TUN_F_TSO_ECN, TUN_F_UFO, TUN_F_USO4, TUN_F_USO6 이다. (https://github.com/torvalds/linux/blob/master/include/uapi/linux/if_tun.h#L88C1-L94C64)
아래의 Offload 부분은 옵션이 ethtool에 의해 활성화 되는지 까지만 확인한 내용이다. 실제 작동 모습과는 다소 다를 수 있다.
아래에서 “수신”과 “발신”은 우리 프로그램의 입장에서 read()를 하는지, write()를 하는지를 기준으로 작성하였다.
즉, 수신이란 커널 → TUN 장치 → 우리의 프로그램 방향이고 (실제로는 NIC를 통해서 데이터가 나가는 방향)
발신이란 우리의 프로그램 → TUN 장치 → 커널 방향이다.
라우터의 시점이라고 생각하면 이해하기 편할 것이다.
offload 사용시 데이터를 수신할 때 MTU 이상의 패킷이 쪼개지지 않고, 하나에 합쳐서 들어온다. 결국 개발자가 보는것은 1개의 패킷이다. 이 패킷을 쪼개는것은 우리가 작성할 코드의 영역이 된다. 용량이 큰 페이로드를 처리할 때 한 번의 syscall로 MSS 만큼의 데이터를 읽을 수 있다.
TUN 장치로 들어오기 전에 패킷의 checksum을 계산하는 것은 비효율 적일 것이다. 어짜피 우리가 각 세그먼트 단위로 패킷을 다시 쪼개고 checksum을 구해야 하기 때문이다. TUN_F_CSUM 옵션을 사용하면 [일반 프로그램 → 커널 → 가상 TUN → 우리가 작성할 프로그램]의 상황에서 커널은 checksum을 하지 않는다.
# Offload 적용전
esukmean@esukmean-mint:/sys/class/net/esm/queues$ ethtool -k esm
Features for esm:
rx-checksumming: off [fixed]
tx-checksumming: off
tx-checksum-ipv4: off [fixed]
tx-checksum-ip-generic: off [requested on]
tx-checksum-ipv6: off [fixed]
tx-checksum-fcoe-crc: off [fixed]
tx-checksum-sctp: off [fixed]
scatter-gather: on
tx-scatter-gather: on
tx-scatter-gather-fraglist: on
tcp-segmentation-offload: off
tx-tcp-segmentation: off [requested on]
tx-tcp-ecn-segmentation: off [requested on]
tx-tcp-mangleid-segmentation: off
tx-tcp6-segmentation: off [requested on]
generic-segmentation-offload: on
generic-receive-offload: on
large-receive-offload: off [fixed]
rx-vlan-offload: off [fixed]
tx-vlan-offload: on
ntuple-filters: off [fixed]
receive-hashing: off [fixed]
highdma: off [fixed]
rx-vlan-filter: off [fixed]
vlan-challenged: off [fixed]
tx-lockless: on [fixed]
netns-local: off [fixed]
tx-gso-robust: off [fixed]
tx-fcoe-segmentation: off [fixed]
tx-gre-segmentation: off [fixed]
tx-gre-csum-segmentation: off [fixed]
tx-ipxip4-segmentation: off [fixed]
tx-ipxip6-segmentation: off [fixed]
tx-udp_tnl-segmentation: off [fixed]
tx-udp_tnl-csum-segmentation: off [fixed]
tx-gso-partial: off [fixed]
tx-tunnel-remcsum-segmentation: off [fixed]
tx-sctp-segmentation: off [fixed]
tx-esp-segmentation: off [fixed]
tx-udp-segmentation: off [requested on]
tx-gso-list: off [fixed]
fcoe-mtu: off [fixed]
tx-nocache-copy: off
loopback: off [fixed]
rx-fcs: off [fixed]
rx-all: off [fixed]
tx-vlan-stag-hw-insert: on
rx-vlan-stag-hw-parse: off [fixed]
rx-vlan-stag-filter: off [fixed]
l2-fwd-offload: off [fixed]
hw-tc-offload: off [fixed]
esp-hw-offload: off [fixed]
esp-tx-csum-hw-offload: off [fixed]
rx-udp_tunnel-port-offload: off [fixed]
tls-hw-tx-offload: off [fixed]
tls-hw-rx-offload: off [fixed]
rx-gro-hw: off [fixed]
tls-hw-record: off [fixed]
rx-gro-list: off
macsec-hw-offload: off [fixed]
rx-udp-gro-forwarding: off
hsr-tag-ins-offload: off [fixed]
hsr-tag-rm-offload: off [fixed]
hsr-fwd-offload: off [fixed]
hsr-dup-offload: off [fixed]
# Offload 적용후 (TSO_ECN 적용 제외)
esukmean@esukmean-mint:/sys/class/net/esm/queues$ ethtool -k esm
Features for esm:
rx-checksumming: off [fixed]
tx-checksumming: on
tx-checksum-ipv4: off [fixed]
tx-checksum-ip-generic: on
tx-checksum-ipv6: off [fixed]
tx-checksum-fcoe-crc: off [fixed]
tx-checksum-sctp: off [fixed]
scatter-gather: on
tx-scatter-gather: on
tx-scatter-gather-fraglist: on
tcp-segmentation-offload: on
tx-tcp-segmentation: on
tx-tcp-ecn-segmentation: off
tx-tcp-mangleid-segmentation: off
tx-tcp6-segmentation: on
generic-segmentation-offload: on
generic-receive-offload: on
large-receive-offload: off [fixed]
rx-vlan-offload: off [fixed]
tx-vlan-offload: on
ntuple-filters: off [fixed]
receive-hashing: off [fixed]
highdma: off [fixed]
rx-vlan-filter: off [fixed]
vlan-challenged: off [fixed]
tx-lockless: on [fixed]
netns-local: off [fixed]
tx-gso-robust: off [fixed]
tx-fcoe-segmentation: off [fixed]
tx-gre-segmentation: off [fixed]
tx-gre-csum-segmentation: off [fixed]
tx-ipxip4-segmentation: off [fixed]
tx-ipxip6-segmentation: off [fixed]
tx-udp_tnl-segmentation: off [fixed]
tx-udp_tnl-csum-segmentation: off [fixed]
tx-gso-partial: off [fixed]
tx-tunnel-remcsum-segmentation: off [fixed]
tx-sctp-segmentation: off [fixed]
tx-esp-segmentation: off [fixed]
tx-udp-segmentation: on
tx-gso-list: off [fixed]
fcoe-mtu: off [fixed]
tx-nocache-copy: off
loopback: off [fixed]
rx-fcs: off [fixed]
rx-all: off [fixed]
tx-vlan-stag-hw-insert: on
rx-vlan-stag-hw-parse: off [fixed]
rx-vlan-stag-filter: off [fixed]
l2-fwd-offload: off [fixed]
hw-tc-offload: off [fixed]
esp-hw-offload: off [fixed]
esp-tx-csum-hw-offload: off [fixed]
rx-udp_tunnel-port-offload: off [fixed]
tls-hw-tx-offload: off [fixed]
tls-hw-rx-offload: off [fixed]
rx-gro-hw: off [fixed]
tls-hw-record: off [fixed]
rx-gro-list: off
macsec-hw-offload: off [fixed]
rx-udp-gro-forwarding: off
hsr-tag-ins-offload: off [fixed]
hsr-tag-rm-offload: off [fixed]
hsr-fwd-offload: off [fixed]
hsr-dup-offload: off [fixed]
프로그램 측에서 Offload와 관련된 정보가 필요할 수 있다. 예를 들어, 지금 들어온 데이터가 TUN_F_CSUM에 의해 체크섬이 계산되지 않았는지 궁금할 수 있다. 이 정보들은 TUN_VNET_HDR을 이용하여 받을 수 있다. 이 옵션을 켜면 위에서 언급한 IFF_NO_PI와 같이 실제 데이터 앞에 virtio_net_hdr 라는 구조체가 붙게 된다. 해당 구조체에서 체크섬을 우리가 직접 해야하는지, Offload가 적용 됐는지 등등을 확인할 수 있다.
문제는 발신, 즉 write() 콜이다. write시에는 어쨋든 MTU에 맞춰서 패킷을 쪼개서 write() 해야 한다. 테스트는 안해봤지만, 인터넷에 널린 글을 봤을때 어쨋든 MTU 이상의 크기를 가진 패킷을 쓰면 안되는것 같다. 또한 write() 하나에 1개의 패킷만을 실을 수 있는것 같다. (애초에 write() 는 1개의 패킷을 발신했다는 것을 의미한다. 그럼에도 어떻게 못하나… 했는데 안되는ᅟ 것 같다.)
그러므로, 작은 패킷들이 빠른 속도로 빈번하게 오고가는 환경이라면 프로그램 단에서 L4 데이터를 합쳐야 할 것으로 보인다.
src_dst_address = (IpAddr, IpAddr);
L4_payload = [u8; MTU 크기 - IP 헤더 크기];
while pkt := tun_queue:
if pkt.src_dst_address != src_dst_address:
write_to_tun(src_dst_address, L4_payload);
src_dst_address = pkt.src_dst_address;
L4_payload.clear();
if L4_payload.remain() < pkt.payload.len():
write_to_tun(src_dst_address, L4_payload);
L4_payload.clear();
L4_payload.extend_from_slice(pkt.payload)마찬가지의 이유로 데이터 수신(read())때 에도, 작은 패킷이 빈번하게 오고간다면 L4 페이로드를 프로그램 단에서 합쳐서 처리하는것이 좋을것 같다. MTU보다 큰 데이터는 TSO로 합쳐서 들어오지만, 작은 패킷은 따로 합쳐져서 들어오진 않는다. 작은 패킷은 어쩔수 없이 패킷마다 read() 를 실행해야 한다. GRO에 의해서 합쳐질 수 있긴 한데, 그럼에도 단일 패킷의 크기가 MTU 보다 커지진 않는다.
멀티코어 시스템 + 멀티 큐를 사용한다면 각 큐 단위에서 L4 페이로드를 합쳐야 할 것으로 보인다. (별도의 설정이 없다면 queue[hash(src addr + dst addr)]로 사용하므로 순서 자체는 문제 없을것 같다. 단, 커널에서 부터 순서가 섞여들어온다면 별도의 처리가 필요할 것이다.)
ICMP를 이용하여 목적지가 없음을 알리기
TUN 장치도 결국 IP주소를 부여하고, 서브넷 내의 네트워크에 통신을 할 것이다. 이때, ICMP를 사용하면 장치·네트워크에 문제가 있음을 알려줄 수 있다. 단순히 Packet을 Drop하여 Timeout을 만드는 것 보다 낫다. 어플리케이션에 정보를 제공하여 문제를 빠르게 식별할 수 있게 도와주기 때문이다.
ICMP의 Destination Unreachable를 이용하면 목적지 IP가 할당되지 않음을 알려줄 수 있다. ICMP는 ping에만 사용되는게 아니다! ICMP의 타입 3번 Destination Unreachable을 사용하면 네트워크 경로상에 있는 라우터, 네트워크 장치 누구나 “네트워크에 이상이 있음”을 통보할 수 있다.
ICMP는 대분류인 타입과 소분류인 코드가 같이 쓰인다. 필자는 소분류 코드로 7번인 Destination host unknown를 사용한다. 의미적으로 해당 장치가 없음을 뜻할 뿐 아니라, Destination host unreachable 등에 비해 발생하는 경우가 적어서 상황 판단에 도움이 되기 때문이다.
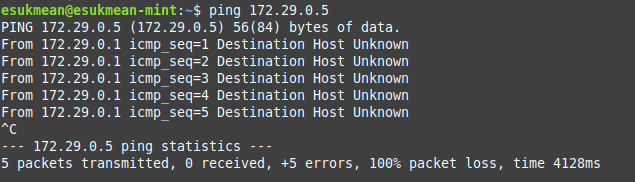
ICMP는 아래와 같은 코드로 생성할 수 있다. 기본적인 ICMP 틀에서 “출발지 주소”, “목적지 주소”, “원래 패킷의 데이터 일부”와 checksum을 맞춰주면 된다.
출발지 주소는 네트워크 상의 아무 라우터 될 수 있다. 이론적으로는 아무 IP나 넣을수 있다는 뜻이다. 그러나, “오류를 발생한 라우터”를 의미하므로 우리의 게이트웨이 IP 주소를 넣으면 된다. 목적지 주소는 TUN에 할당된 IP주소를 입력하면 된다.
그리고 28~56번째에 기존 패킷 데이터를 집어넣는다. (0-index 기준) 첫 20바이트는 IPv4 헤더 크기와 일치한다. 다음 8바이트는 L4의 헤더의 첫 8byte 부분인데, 왠만해서 출발지·목적지 포트를 저장되어 있다. 커널은 이 28바이트로 IP헤더와 L4 헤더를 분석하여 어느 통신(스트림)에서 문제가 생긴것인지 판단한다.
fn generate_icmp_no_route_to_host_reply(original: [u8; 28]) -> [u8; 56] {
let mut packet = [0u8; 56];
// IP Header
packet[0] = 0x45; // Version and IHL (IPv4, 20 bytes)
packet[1] = 0x00; // Type of Service
packet[2] = 0x00; // Total Length (2 bytes, will be calculated later)
packet[3] = 56; //
packet[4] = 0x00; // Identification (2 bytes)
packet[5] = 0x00;
packet[6] = 0x00; // Flags/Fragment Offset
packet[7] = 0x00;
packet[8] = 0x40; // TTL (64)
packet[9] = 0x01; // Protocol (ICMP)
packet[10] = 0x00; // Header Checksum (2 bytes, will be calculated later)
packet[11] = 0x00;
packet[12..16].copy_from_slice(&[172, 29, 0, 1]); // Source IP (Placeholder)
packet[16..20].copy_from_slice(&[172, 29, 0, 2]); // Destination IP (Placeholder)
// ICMP Header
packet[20] = 0x03; // ICMP Type: Destination Unreachable
packet[21] = 7; // ICMP Code: Host Unreachable
packet[22] = 0x00; // Checksum (2 bytes, will be calculated later)
packet[23] = 0x00;
packet[24] = 0x00; // Unused (4 bytes)
packet[25] = 0x00;
packet[26] = 0x00;
packet[27] = 0x00;
// Original IP Header and first 8 bytes of the original data (Placeholder)
packet[28..56].copy_from_slice(&original);
// Calculate checksum for ICMP header and data (20: IPv4, 8: 실제 데이터)
let checksum = Self::compute_checksum(&packet[20..28 + 20 + 8]);
packet[22] = (checksum >> 8) as u8;
packet[23] = (checksum & 0xff) as u8;
// Calculate checksum for IP header
let ip_checksum = Self::compute_checksum(&packet[0..20]);
packet[10] = (ip_checksum >> 8) as u8;
packet[11] = (ip_checksum & 0xff) as u8;
packet
}
fn compute_checksum(data: &[u8]) -> u16 {
let mut sum = 0u32;
// Sum all 16-bit words
for i in (0..data.len()).step_by(2) {
let word = u16::from_be_bytes([data[i], data[i + 1]]);
sum = sum.wrapping_add(u32::from(word));
}
// Fold 32-bit sum to 16 bits
while (sum >> 16) > 0 {
sum = (sum & 0xffff) + (sum >> 16);
}
!(sum as u16)
}정상적으로 설정됐다면 curl 등으로 접속 테스트를 했을때, 그 즉시 연결 실패 오류가 발생할 것이다. Timeout까지 갈 것 없이 OS에서 ICMP를 근거로 연결을 중지할 것이다.




답글 남기기