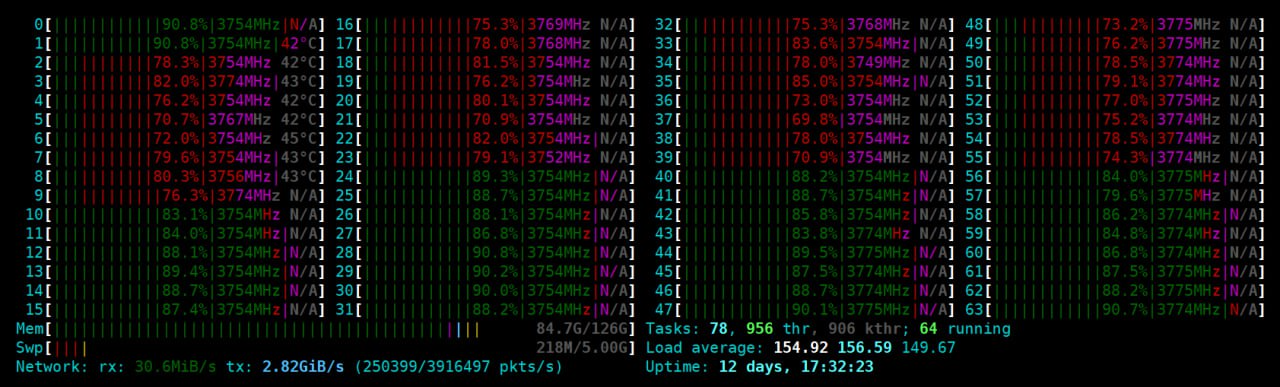
이번 글은 이전에 쓴 WebRTC 서비스에서 적용한 것들을 정리했습니다. 그러다 보니 범위가 넓습니다.
WebRTC 관련 글:
환경
- Rust (nightly, cold_path, likely_unlikely, generic_const_exprs를 사용하기 위함)
- Server: AMD EPYC 9454 48-Core Processor (96core), Mellanox ConnetEx-5 (25Gbps)
32Core(64Thread)에서도 문제는 없었지만, CPU 여유를 위해 48Core(96Thread)로 서버를 상향했다.
Rust (프로그램)
주의: 아래 내용은 samply로 performance profiling을 한 결과를 바탕으로 적용한 조치입니다.
로직과 아키텍처에 따라서 오히려 오버헤드가 발생할 수도 있으니, 적용시 samply 등의 프로파일러를 통해 직접 수치 비교를 하시길 바랍니다.
프로그램 최적화 하는것이 성능 최적화의 80% 정도 된다. 사실 커널이나 NIC 튜닝은 극한의 성능을 뽑아낼 때, 또는 패킷 로스가 발생할 때나 필요하다. 왠만한 수준에서는 프로그램을 튜닝하는게 성능을 올리는 확실한 방법이다.
프로그램을 튜닝하기 위해서는 프로파일링 도구가 필요하다. 프로파일링 도구 없이는 감으로 의존해야 하는데, 이는 때때로 틀린 추측치를 준다. 그러니까 반드시 프로파일러를 사용하자.
재작년에만 해도 flamegraph 밖에 없었던것 같은데, 올해 찾아보니 samply 라는 도구가 생겼다. samply를 써보도록 하자.
필자의 경우 성능에 대한 요구사항이 존재했다. 그래서 성능적 요구사항에 맞추기 위해 아래 수준의 작업을 했다.
꽤나 시간이 많이 드는 작업이므로 비즈니스적 요구사항이 널널하다면 적당히 하는것을 추천한다.
네트워크 전용 쓰레드 사용
네트워크를 엄청 많이 쓰는 프로그램이라면 비동기 보다 busy-polling을 쓰는것이 낫다. timeout을 잘만 활용하면 처리량은 높이면서도 대기시에도 적은 CPU 사용량을 기대 할 수 있다. 이것을 위해서는 네트워크 전담 쓰레드를 만들 필요가 있다.
그리고 네트워크 전담 쓰레드와 실제 사용자 처리 쓰레드를 core-affinity로 분리하는것이 좋다. htop 과 같은 도구에서 user / kernel에 의한 cpu 사용량이 얼마인지를 직관적으로 알 수 있다. 또한, context-switching에 대한 비용을 줄일 수 있다.
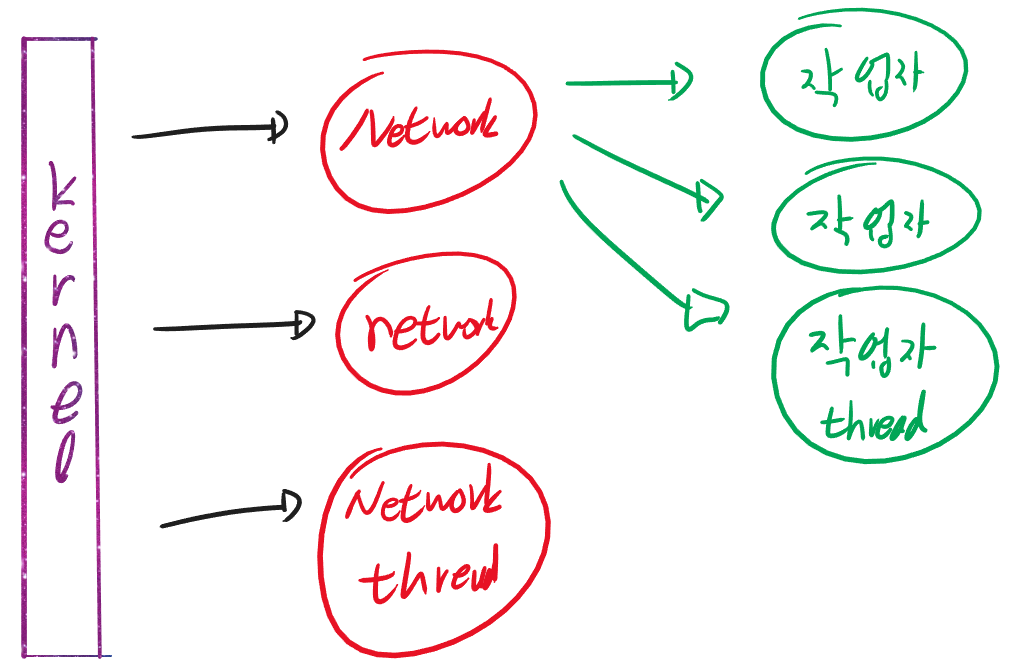
커널 - 네트워크 쓰레드 - 작업자 쓰레드를 배치하면 된다. 그러면 걱정이 생길 수 있다. 작업자 A로 패킷이 가려면 네트워크 쓰레드 A 에 패킷이 와야한다. 만약 네트워크 쓰레드 B로 패킷이 들어간다면 결과적으로 작업자 쓰레드는 패킷을 수신하지 못한 셈이 된다. 그로 인해 실질적인 패킷 로스가 발생할 수 있다.
이 문제는 rx-hashing을 이용하면 해결 가능하다. 좋은 NIC는 여러개의 내부 큐를 가진다. 이때, rx-hashing의 조건에 따라 어느 큐로 데이터를 보낼지 결정한다. irq-balance를 사용하지 않는다면 패킷은 커널의 특정 쓰레드로 들어간다. 그러면 커널은 해당 쓰레드에서 처리 후 특정 쓰레드로만 패킷을 전달한다.
우리는 발신지 ip와 port를 조건으로 걸었다. 즉, thread[hash(src_ip, src_port) % thread.len()] 로 유일하게 패킷이 들어간다.
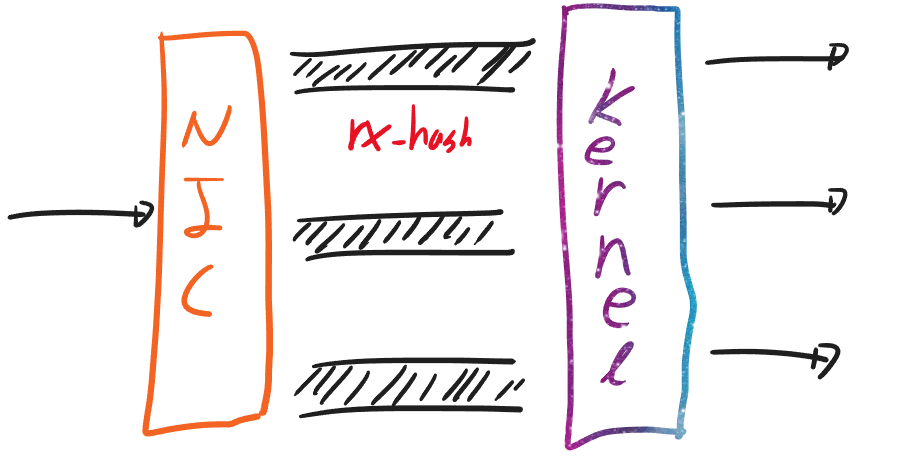
단, 이것을 충분히 활용하기 위해서는 dup 대신 SO_REUSEPORT 등을 이용해서 소켓을 아예 새로 만들어야 한다. dup을 쓴다면 커널이 하나의 소켓 큐에 데이터를 넣는다. 하지만 각 네트워크 쓰레드가 경쟁적으로 데이터를 가져가기 때문에 스티어링 문제가 발생한다.
큰 데이터를 여러번 채널로 이동시 Box로 이동
우리가 만든 WebRTC 프로그램은 수십만명이 빈번하게 들어오는것을 타겟팅 했다. 1초에 수천명이 들어왔다 나갔다 할 수도 있다. 초기 접속을 받기 위해서는 여러 연결(IP Endpoint) 후보군에서 들어오는 패킷을 처리해 줘야 한다.
개략적으로 [Load Balancer에서 접속정보 전달 (WebRTC 객체 생성) -> STUN binding 전용 처리 쓰레드 -> 네트워크 쓰레드 -> 하위에 있는 작업자 쓰레드] 로 객체 하나가 4번을 움직이는 구조였다. 그리고 struct 하나가 600Byte 정도를 차지했다. 그러다보니 매 차례 객체가 이동하거나 사라질 때 마다 600Byte의 데이터가 복사되는 문제가 있었다.
커널/NIC 섹션에서 설명하겠지만, 우리는 rx-hashing을 이용했다.
struct 크기는 clippy의 경고 메세지를 통해 확인했다.
이정도 크기는 Box에 감싸서 포인터(Reference)만 이동하는것이 낫다. 그러면 실제 데이터는 거의 움직이지 않고, 전달 되는것은 포인터 뿐이다.
Pin을 사용하면 메모리 위치를 움직이지 않는것을 보장할 수 있다. (우린 Pin까진 쓰지 않았다.)
numa 적용
서버급 CPU에서는 NUMA 라는 개념이 들어간다. 쉽게 이야기 하자면, CPU 코어를 4개 그룹으로 묶는다. 그리고 각 그룹은 지정된 메모리 공간을 마음껏 쓸 수 있다. 만약 다른 그룹의 공간에 접근할 경우 추가적인 절차가 필요하다 (numa remote-access) 그러므로, 최대한 내 메모리 공간에 데이터를 둬야 한다.
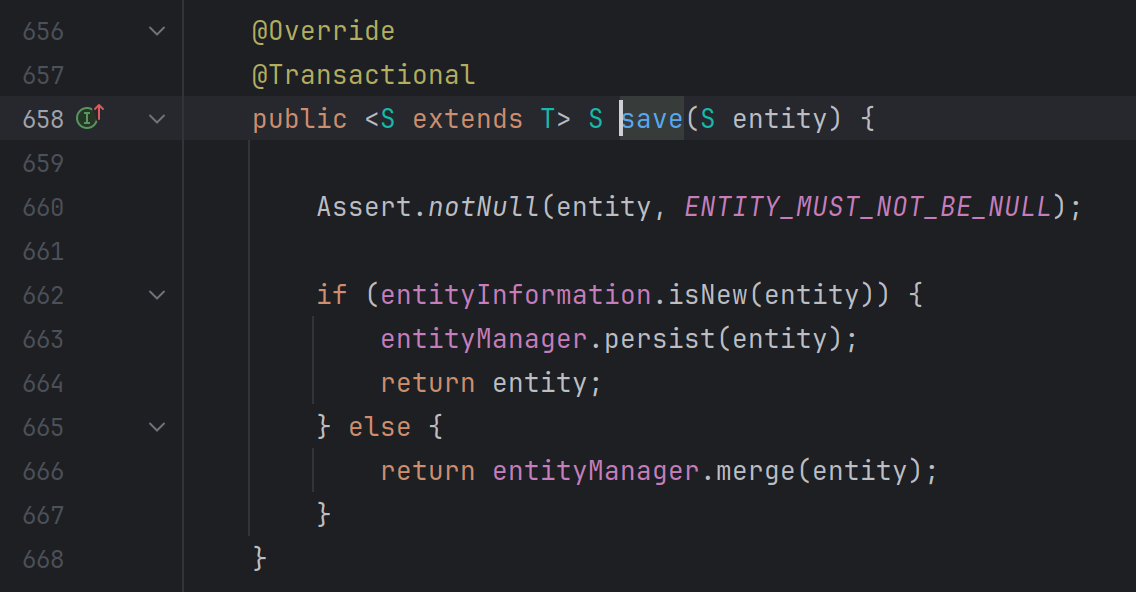
상술한 [네트워크 쓰레드 - 작업자 쓰레드] 도 하나의 NUMA 그룹 내에서만 작동되게 했다. 패킷 데이터들이 같은 NUMA 그룹에서 움직이므로 메모리 접근에 속도 하락이 없어진다.
여기에 한발 더 나가서, 우리는 WebRTC 객체를 Box로 움직인다고 했었다. 맨 마지막 작업자 쓰레드 또한 Box 째로 객체를 가진다. Vec<Box<WebRTCClient>> 이때 모든것은 아니더라도, WebRTC Client를 내 쓰레드에서 한번 까고 (inner를 열고), 다시 Box에 감싸는 것으로 얕은 복사를 이룰 수 있다.
MessageExchange::AddHandshakedClient(mut client, cred, pkt) => {
let mut client = std::hint::black_box(*client);
let idx = self.client_freelist.pop().map(|i| i.0).unwrap_or_else(|| {
self.client.push(None);
self.client.len() - 1
});
self.connected_user_count += 1;
self.stun_table.insert(cred.clone(), idx);
self.stun_table_rev.insert(idx, cred);
if let Some(addr) = client.nominated_remote_addr().first() {
// 보장: AddClient 메세지를 보내기 전에 주소들을 정리함.
self.nat_table.insert(*addr, idx);
self.nat_table_rev.insert(idx, *addr);
}
client.receive(pkt);
self.client[idx] = Some(Box::new(client));
}물론, 이미 내부에 할당된 버퍼까지는 현재 numa node로 넘겨올 수 없다. 하지만 shallow copy만으로도 뭔가 빨라진 느낌이 들었다. 폴라시보 효과인것 같기도 하다.
heap에 들어가 있는 Vec등은 복사되지 않는다는 말이다.
NUMA를 제대로 쓰기 위해서는 Core affinity 설정이 반드시 필요하다. 그렇지 않다면 다른 numa node로 스케쥴링이 넘어갈 수 있다.
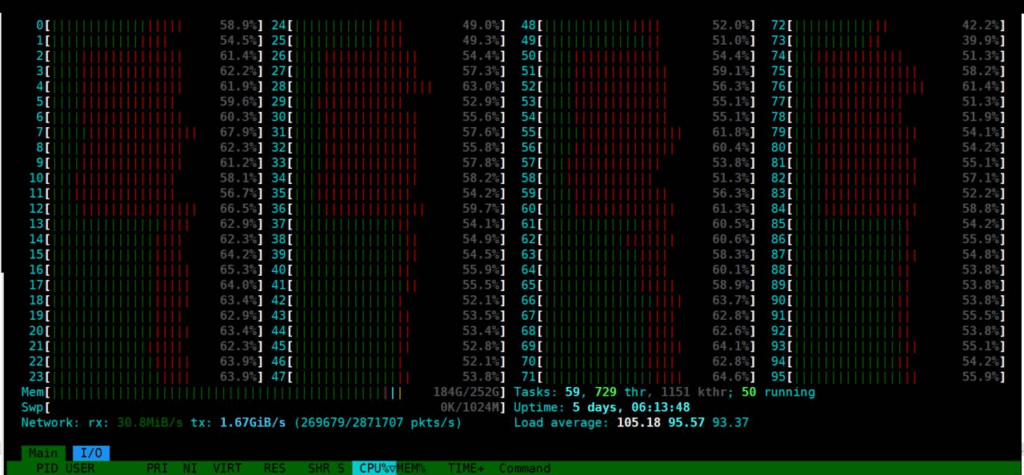
(Soft-IRQ 같은것이 표시되어 있지 않아서 빨간색이 조금 많아 보인다)
메모리 할당·해제는 최소화
이 부분은 필자도 간과했던 부분이다. 솔직히 말하자면 Byte로 어느정도 됐다고 생각했는데, 프로파일링을 해 보니까 이쪽의 시간 점유가 엄청 많았다.
하나의 25Gbps 서버에 수만명이 접속을 한다. 효율적인 처리를 위해 패킷 송·수신은 channel(Crossbeam::ArrayQueue)로 이루어졌다. 1초에 4백만개의 패킷이 ArrayQueue로 들어간다면 동기화 비용에만 시간을 꽤 쓸 것이다. 그래서 Vec<packets> 를 Array Queue로 보냈다.
하나의 RTP 패킷이 들어오면, 그것이 접속자 수 만큼 복제되는 방식이었다. 그러다 보니 Vec의 생성·삭제가 너무 빈번해 졌다. Vec::with_capacity를 통해 적당한 크기로 벡터를 만들었음에도 매 루프마다 생성되고 삭제되는게 너무 큰 비용이 됐던 것이다. 게다가 새로 만들어진 Vec는 매 순간 page-fault가 발생했다.
그래서, 이것 전용으로 메모리 풀을 만들었다. Vec를 매번 생성·삭제 하는것 보다는 조금의 동기화 비용을 주더라도 재활용 하는것이 비용이 더 저렴했다. 실제로도 userland cpu가 약 4% 정도 절감 됐다.
Peak 치에서 htop의 초록색 막대기가 두 칸 정도 줄었다. 최대 8% 정도 까지 CPU를 아낀 셈이 되기도 한다.
Memory Pool
use crossbeam::queue::ArrayQueue;
use std::ops::{Deref, DerefMut};
use std::sync::{Arc, Weak};
pub struct MemoryPool<T> {
queue: ArrayQueue<Vec<T>>,
}
impl<T> MemoryPool<T> {
pub fn new(capacity: usize) -> Self {
Self {
queue: ArrayQueue::new(capacity),
}
}
pub fn fill_buffer(&self, count: usize, inner_size: usize) {
if self.queue.len() >= count {
return;
}
let size = count - self.queue.len();
for _ in 0..size {
self.queue.push(Vec::with_capacity(inner_size));
}
}
pub fn get(self: &Arc<Self>, default_size: usize) -> PooledVec<T> {
let vec = self
.queue
.pop()
.unwrap_or_else(|| Vec::with_capacity(default_size));
PooledVec(vec, Arc::downgrade(self))
}
pub(crate) fn put(self: &Arc<Self>, vec: Vec<T>) {
// 버퍼가 꽉차면 버려짐
self.queue.push(vec);
}
pub fn len(&self) -> usize {
self.queue.len()
}
}
pub struct PooledVec<T>(Vec<T>, Weak<MemoryPool<T>>);
impl<T> PooledVec<T> {
pub fn new_dangling(v: Vec<T>) -> Self {
Self(v, Weak::new())
}
}
impl<T> Drop for PooledVec<T> {
fn drop(&mut self) {
if let Some(pool) = self.1.upgrade() {
let mut vec = std::mem::take(&mut self.0);
vec.clear();
pool.put(vec);
}
}
}
impl<T> AsRef<Vec<T>> for PooledVec<T> {
fn as_ref(&self) -> &Vec<T> {
&self.0
}
}
impl<T> AsMut<Vec<T>> for PooledVec<T> {
fn as_mut(&mut self) -> &mut Vec<T> {
&mut self.0
}
}
impl<T> Deref for PooledVec<T> {
type Target = Vec<T>;
fn deref(&self) -> &Self::Target {
&self.0
}
}
impl<T> DerefMut for PooledVec<T> {
fn deref_mut(&mut self) -> &mut Self::Target {
&mut self.0
}
}shirnk 부분은 직접 구현해야 한다. get에서도 최소 수량이 없으면 reserve 하는 로직등이 추가되면 좋다. 하지만 초석으로 쓰기엔 괜찮을 수준이다.
버퍼 부분도 마찬가지이다. 우리 같은 경우에는 libc의 sendmmsg와 recvmmsg 를 통해 직접 패킷을 송·수신 하고 있었는데, UIO_MAXIOV (= 1,024) 개의 버퍼를 매번 만들었다. 맨 위의 htop 캡쳐를 보면 초당 패킷수가 400만이 된다. 거진 초당 4천번의 메모리 할당·해제가 발생한다. 이정도가 되니까 매모리 할당 비용만 해도 너무 커졌었다.
그래서 버퍼를 최대한 재활용 하는 방향으로 패치를 했더니 성능이 10%는 높아졌다. 이미 1,024개의 요청을 ByteMut로 묶었지만, 그걸로는 부족했던 것이다.
이것 또한 NUMA를 고려해서 numa 그룹별로 메모리 풀을 관리하도록 구성했다.
메모리 복사도 ㄴㄴ (Vectored IO)
또 하나 중요한 것은 iov를 잘 써야 한다는 것이다. 기존에는 편의상 작업자 쓰레드가 패킷 내용을 전달해 주고 -> 내용을 네트워크 쓰레드로 복사를 했었다. 그러다 보니 메모리 복사가 계속해서 발생했었다. 패킷 수 만큼의 복사는 물론, 25Gbps * 2의 메모리 대역폭도 상시 사용 했다
Vectored IO를 사용하면 이 문제가 해결된다. (물론 파이프라인을 잘 구성해야 한다.) 그러면 WebRTC 객체에서 생성한 데이터를 데이터 복사 없이 sendmmsg까지 보낼 수 있다.
전송측 코드
pub fn send_transmits_iov<const GUARANTEED: bool>(
&self,
transmits: &[PooledVec<Transmit>],
alloc: &mut TransmitAllocCache,
) -> usize {
let mut idx = 0;
let mut real_sent = 0usize;
let fd = self.sock.as_raw_fd();
for pkts in transmits.iter() {
for pkt in pkts.iter() {
if idx >= PROCESS_ARRAY_SIZE {
real_sent +=
Self::send_transmits_internal::<GUARANTEED>(fd, alloc, PROCESS_ARRAY_SIZE);
idx = 0;
}
alloc.iovecs[idx] = iovec {
// WebRTC에서 생성한 데이터를 포인터로 전달함
iov_base: pkt.contents.as_ptr() as *mut _,
iov_len: pkt.contents.len(),
};
let (namelen, name_ptr) = Self::msg_name_packing::<PROCESS_ARRAY_SIZE>(
pkt.destination,
&mut alloc.addrs[idx],
);
alloc.msgs[idx] = mmsghdr {
msg_len: 0,
msg_hdr: msghdr {
msg_name: name_ptr,
msg_namelen: namelen,
msg_iov: &mut alloc.iovecs[idx],
msg_iovlen: 1,
msg_control: std::ptr::null_mut(),
msg_controllen: 0,
msg_flags: 0,
},
};
idx += 1;
}
}
if idx > 0 {
real_sent += Self::send_transmits_internal::<GUARANTEED>(fd, alloc, idx);
}
real_sent
}
이 코드의 핵심은, (1) 1,024만큼의 maxiov 배열도 딱 한번만 생성 후 재활용 한다는 것과 (2) WebRTC 객체에서 생성한 데이터를 sendmmsg 까지 끌고오게 해야한다는 것이다.
첫 글에서 언급했던것 처럼, 패킷 전송시 sendmmsg와 recvmmsg를 사용해야지 대용량 처리가 가능하다. sendmsg와 같이 배치 처리가 안되는 커널 함수를 사용하면 오버헤드가 꽤 붙는다.
메모리 할당시 zeroized는 피하기
처음에 ByteMut을 사용할 때 버퍼를 초기화 하기 위해 BytesMut::zeroed 를 사용했었다. 결론만 말하자면 0으로 초기화 하는것은 CPU 시간을 엄청 먹는다. samply로 찍어보면 이 함수 하나가 다른 여타 함수들 보다 시간을 더 잡아 먹는것을 알 수 있다.
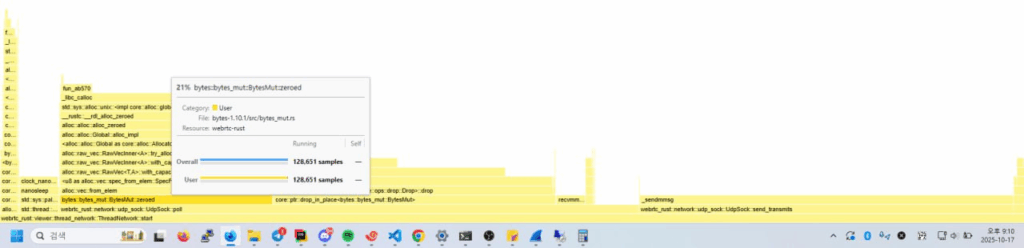
옆에 살짝 보인것 처럼 bytemut drop에도 꽤 긴 시간이 걸린다. 가능하면 큰 덩어리의 ByteMut을 사용하자.
이것은 BytesMut 뿐 아니라 vec![0u8; 1024] 와 같은 곳에서도 동일하다. 가능하면 직접 0으로 초기화 하지 말자.
올바른 방법은 BytesMut에서는 아래 처럼 with_capacity로 공간 할당 후 set_len()을 통해 크기를 고정하는 것이다. 어짜피 recvmmsg / sendmmsg 에서 필요한 데이터를 복사하기 때문에 안에 찌꺼기 값이 들어가 있어도 괜찮다. 읽을때만 정확한 길이(msg_len)를 읽으면 된다.
samply로 찍어보니 0으로 데이터를 넣는것도 libc의 함수로 돌아가는것을 확인했다. 그럼에도 엄청 느렸다.
let mut bufs = BytesMut::with_capacity(dst_size * BUF_SIZE);
unsafe {
bufs.set_len(dst_size * BUF_SIZE);
}
// 이렇게 통으로 할당 받고나서 split_to로 쪼개준다. 그러면 dst_size 만큼의 버퍼가 모두 drop 됐을때 딱 한번만 bytesmut이 메모리에서 해제된다.
alloc.bufs[i] = bufs.split_to(BUF_SIZE);
let buf_ptr = alloc.bufs[i].as_mut_ptr();
alloc.io_vecs[i] = iovec {
iov_base: buf_ptr as *mut c_void,
iov_len: BUF_SIZE,
};Vector에서는 dst.spare_capacity_mut() 를 사용할 수 있다. 근데 Vector::push가 이미 잘 최적화 되어있기 때문에, 여기까지 올 필요는 없다. 필자는 1,024개 패킷을 vector에 push할 때 사용을 했긴 했지만 눈에 보이는 성능 향상은 없었다.
let mut dst = Vec::with_capacity(1024);
let dst_ptr = dst.spare_capacity_mut();
let batch_size = usize::min(UIO_MAXIOV, dst.capacity() - dst.len());
let recv_count = unsafe {
recvmmsg(sock_fd, alloc.msgs.as_mut_ptr(), batch_size as libc::c_uint, 0, std::ptr::from_ref(&timeout).cast_mut())
};
...
let mut dst_target_idx = dst.len();
for i in 0..recv_count as usize {
let pkt_ptr = &mut alloc.bufs[i];
let pkt = ...;
dst_ptr[dst_target_idx].write(pkt);
dst_target_idx += 1;
}
unsafe { dst.set_len(dst_target_idx) };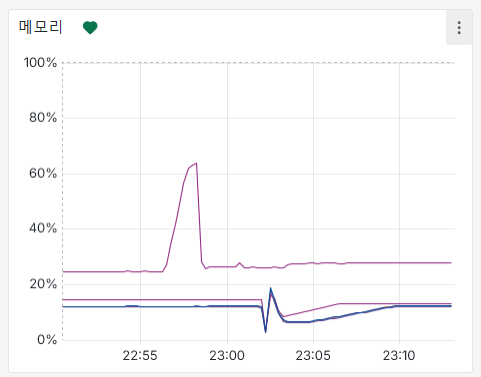
128GB를 0으로 채우는데 몇 초가 걸린다.
Generic Const 사용
Rust에는 Generic Const 라는것이 있다. 이것은 컴파일 타임에 다른 실행 경로를 만들어준다.
예를 들어, 아래와 같이 <const GUARANTEED: bool> 를 붙였다고 하자. 그러면 컴파일 타임에 두개의 함수가 생긴다. 빈번하게 동작하는 매번 런타임에 값을 체크 하는 대신, 별도의 경로를 쓰게 함으로서 성능을 아주 살짝 늘릴 수 있다.
사실 이것도 눈에 보이는 성능 향상은 없었다. 약간 마음의 위안 같은 느낌이긴 하다.
pub fn send_transmits_iov<const GUARANTEED: bool>(
&self,
transmits: &[PooledVec<Transmit>],
alloc: &mut TransmitAllocCache,
) -> usize {
for ... {
let is_success = sendmmsg(...)
if GUARANTEED && !is_success {
// 실패시 다시 시도
continue;
}
}
}cold-path 또는 likely, unlikely 사용
동일하게 눈으로 체감되는 성능 향상은 없었다. 그러나 메타 테그 급으로도 사용할 수 있어서 다룬다.
Rust는 LLVM을 컴파일 백앤드로 사용하는데, LLVM에는 메타 명령어로 “이 블록”이 얼마나 자주 호출될 지를 알려 줄 수 있다. 이것을 활용하면 if문에 “자주 사용하지 않는 if문임” 또는 “자주 사용되는 if문임” 등의 정보를 컴파일러에게 알려 줄 수 있다.
블록에 “자주 사용되지 않음”을 표시하려면 cold_path()를, boolean에 true일 가능성이 높음/낮음을 표기할 때는 likely(bool) -> bool, unlikely(bool) -> bool을 사용한다
이것을 통해 코드 배치 최적화를 기대할 수 있다. 예를 들어, 코드에 방어용으로 매번 “WebRTC가 연결되어있는지 검증”하는 if문이 있다고 하자. disconnected 상태면 이벤트로서 이미 밖에 나갔을 것이지만, 혹시 모를 data-race등을 방지하기 위해 if문을 썻다.
pub fn poll_outgoing<const PROPAGATE_LEN: usize, const IS_BROADCASTER: bool>(
&mut self,
tx: &mut Vec<Packet>
) -> bool {
if std::hint::unlikely(!self.rtc.is_alive()) {
return false;
}
...
}
이 경우, unlikely를 사용하면 이 if 블록은 자주 접근 되지 않을것임을 컴파일러에게 알려줄 수 있다. 그러면 명령어 배치를 저 멀리에 두고, 원래 코드 흐름이 연속으로 이어지게 코드를 배치할 가능성이 높다.
남용만 하지 않는다면 다른 사람에게 “이 if문은 거의 동작안함”을 알려주는 의미도 생기기에 좋은 것 같다.
L1-I Cache까지 가야지 효과가 있을것 같긴하다.
한편, cold_path()도 존재한다. 이것은 함수 또는 코드 블록에 적용할 수 있다. 이러면 해당 코드 블록은 거의 실행되지 않을것임을 알려 줄 수 있다. 마찬가지로 코드 배치시에 캐시 지역성 쪽으로 영향을 줄 것이다.
if std::hint::unlikely(should_renegotiate) {
for client_idx in room.iter() {
let Some(client) = self.client[*client_idx].as_mut() else {
std::hint::cold_path();
continue;
};
client.handle_track_open_commit();
}
}커널 · NIC 부분
rx-hashing
첫 문단에서 rx-hashing를 언급했다. 이것은 수신되는 패킷을 어느 큐로 넣을 것인지를 정하는 방법이다. 이것을 사용하려면 우선 NIC가 지원하는지 부터 확인해야 한다. 필요 조건은 (1) NIC에서 멀티 큐를 지원 (2) NIC에서 rx-hashing 기능을 지원한다는 두가지 조건을 모두 충족 해야한다.
우선 멀티 큐를 지원하는지 확인해 보자. ethtool -l <nic> 를 실행하면 몇개의 큐가 있는지 확인할 수 있다. 아래의 경우에는 63개의 큐가 있음을 볼 수 있다. 말로 풀어보자면, 패킷 수·발신 시에 63개의 큐로 커널과 교신한다는 의미다.
ethtool -l ens3f0np0
Channel parameters for ens3f0np0:
Pre-set maximums:
RX: n/a
TX: n/a
Other: n/a
Combined: 63
Current hardware settings:
RX: n/a
TX: n/a
Other: n/a
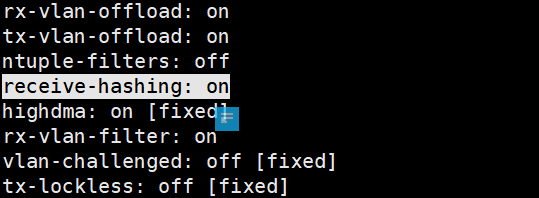
Combined: 63이제 rx-hashing 기능이 있는지 확인 해 봐야 한다. receive-hashing 또는 유사한 기능이 NIC에 있는지 확인해야 한다.
ethtool -k ens3f0np0
...
receive-hashing: on
...
만약 두가지 조건이 충족한다면 rx-hash를 사용할 수 있다. 아래의 명령어로 설정할 수 있다.
ethtool -N ens3f0np0 rx-flow-hash udp4 sf여기서 체크해야 할 부분은 udp4와 sf 부분이다. 프로토콜마다 무엇을 해시키로 사용할 지 정할 수 있다. 자세한 것은 ethtool man 을 확인하자. 중요한 부분만 발췌하자면 아래의 프로토콜을 지정할 수 있고,
tcp4 TCP over IPv4
udp4 UDP over IPv4
ah4 IPSEC AH over IPv4
esp4 IPSEC ESP over IPv4
sctp4 SCTP over IPv4
tcp6 TCP over IPv6
udp6 UDP over IPv6
ah6 IPSEC AH over IPv6
esp6 IPSEC ESP over IPv6
sctp6 SCTP over IPv6다음으로 해시 키를 지정할 수 있다
m : 수신하는 NIC의 Mac 주소
v : 패킷의 vlan tag
t : 패킷의 프로토콜 필드
s: 출발지 IP 주소
d: 목적지 IP 주소
f: 출발지 포트
n: 목적지 포트일반적으로는 sdfn 만을 사용한다. 왠만해선 d하고 n옵션도 동일할 것이므로, 실질적으로 s,f 옵션만 건들면 된다.
즉, udp4 sf 를 지정했다는 말은 UDP (IPv4) 패킷은 출발지의 IP주소와 포트 가 같을때 동일한 쓰레드로 패킷이 들어가게 하겠다는 의미가 된다. 이것을 통해서 패킷 흐름에 제약을 걸 수 있으며, 더 나아가서 효율적인 구조 설계가 가능해 진다.
제대로 지정이 됐다면 ethtool -n ens3f0np0 rx-flow-hash udp4 로 설정한 키를 확인할 수 있으며,

ethtool -x ens3f0np0 로 해시 값(=256)에 따라서 어느 큐에 데이터가 들어갈 지를 확인 가능하다.
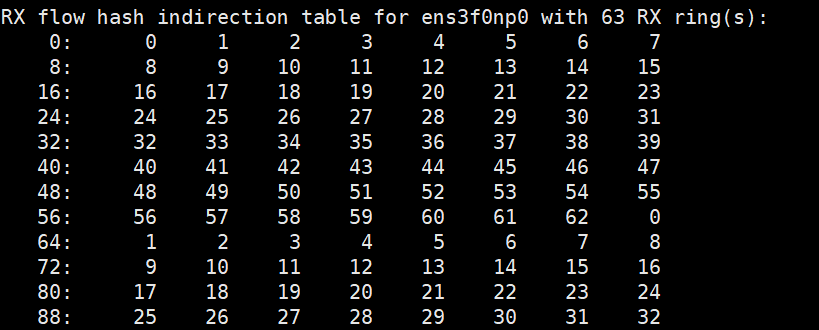
기본적으로는 toeplitz 라는 해시 함수를 사용한다.
sendbuffer
어플리케이션에서 sendmmsg로 데이터를 커널에게 보냈다. 이 데이터가 들어갈 충분한 버퍼가 존재한다면 blocking 없이 데이터가 써질 것이다. 그렇기에 커널 버퍼를 충분히 만들어 주는것이 좋다.
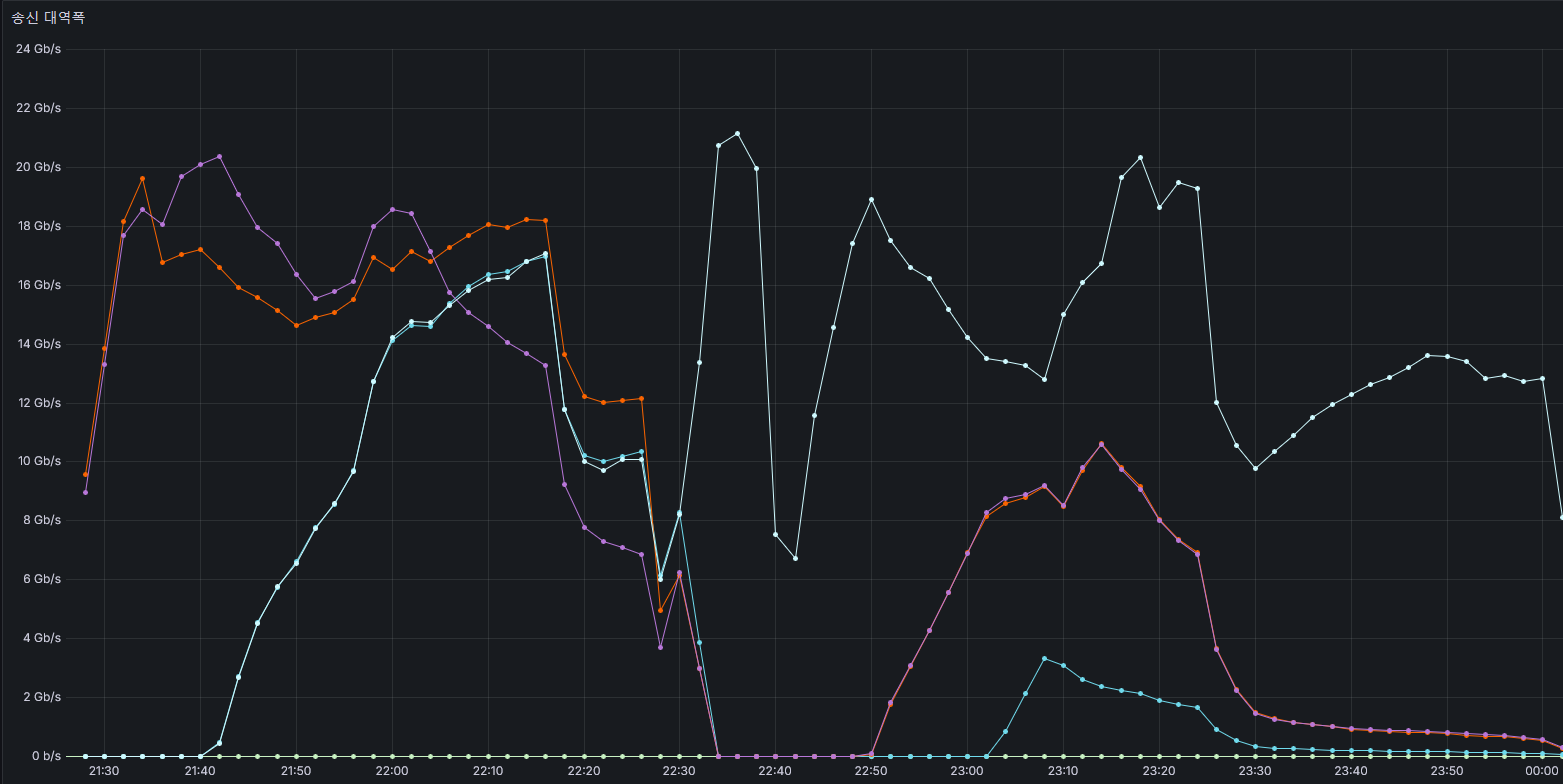
필자도 16Gbps 이상으로 데이터를 송신하자 일부 패킷 로스가 발생하며 알게됐다.
sendmmsg, sendmsg의 책임은 커널 버퍼에 데이터를 넣는것 까지이다. blocking이 됐다는 것은 커널측 소켓 버퍼에 남은 용량이 없다는 의미이다.
netstat -suna 를 실행했을때 send buffer errors에 숫자가 올라가 있다면 어플리케이션 단의 SND_BUF 크기를 늘려줘야 한다.
Send Buffer 설정
const BUF_64MB: libc::c_int = 64 * 1024 * 1024;
const BUF_32MB: libc::c_int = 32 * 1024 * 1024;
unsafe {
libc::setsockopt(
sock.as_raw_fd(),
libc::SOL_SOCKET,
libc::SO_RCVBUF,
&BUF_32MB as *const _ as *const libc::c_void,
std::mem::size_of::<libc::c_int>() as libc::socklen_t,
);
}
unsafe {
libc::setsockopt(
sock.as_raw_fd(),
libc::SOL_SOCKET,
libc::SO_SNDBUF,
&BUF_64MB as *const _ as *const libc::c_void,
std::mem::size_of::<libc::c_int>() as libc::socklen_t,
);
}
필자는 네트워크 쓰레드만 30개 정도 되므로 64MB로 send buffer를 설정했었다. 본인에게 맞는 숫자를 찾자.
참고로, 커널 내 UDP buffer의 최대 크기도 설정해야 할 수 있다. 이 값은 sysctl에서 제어할 수 있다. 이 값이 낮으면 어플리케이션에서 SO_SNDBUF를 설정해도 거부될 수 있다.
net.core.wmem_max = 134217728
net.core.rmem_max = 134217728
net.core.wmem_default = 4194304
net.core.rmem_default = 4194304
net.ipv4.udp_mem = 6165207 8220276 12330414
# udp용 버퍼로 25GB는 할당 가능. 33GB 정도 부터 메모리 관리 시작, 최대 50GB 사용필자의 경우에는 wmem, rmem 부분만 sysctl.conf 에 정의했다. net.ipv4.udp_mem는 시스템이 알아서 정한것 같은데, 짜피 메모리가 충분하므로 따로 수정하지 않았다.
Qdisc
다음은 qdisc 이다. 사용자가 udp socket에 데이터를 작성하면 kernel에서 qdisc라는 곳으로 넘어간다. qdisc는 실제 NIC의 queue와 매핑되어 있는 공간이다. (ethtool -l ens3f0np0 의 큐와 매핑되어 있다)
마찬가지로, 여기에 메모리가 부족하면 NIC로 가기도 전에 패킷 드롭이 발생할 수도 있다. 이것은 tc -s qdisc show dev ens3f0np0 을 통해서 확인 가능하다
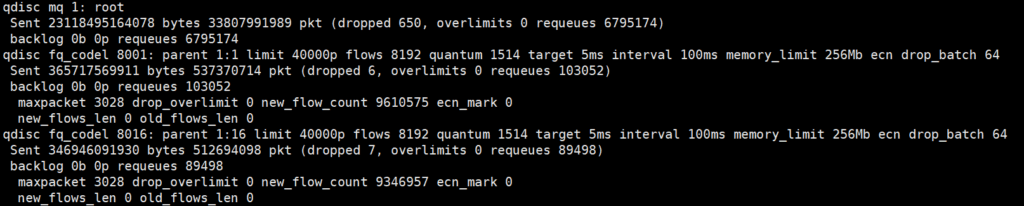
필자의 경우에는 기본값인 상태일때 20Gbps 부근에서 드롭이 간간히 있었어서 넉넉하게 메모리를 부여했다. (메모리가 제일 싼 자원이다) 지금 같은 경우에는 256Mb의 큐 공간을 부여한 상태이다.
qdisc는 설정하기가 나름 까다롭다. parenet를 찾고, 기존것을 제거하거나 교체하는 방식으로 수정해야 하기 때문이다. 그러므로, 이것은 tc -s qdisc show dev ens3f0np0 등의 결과를 통으로 복사해서 GPT에 집어넣자. GPT에게 fq_codel limit 40000 flows 8192 quantum 1514 target 5ms interval 100ms memory_limit 256Mb 가 설정되게 해달라고 하면 된다.
이 값은 메모리가 널널하기 때문에 쓴 값이다. 혹시나 시스템 메모리가 부족하다면 조금 낮은 수치를 사용해도 된다.
limit 40000 이라는 수치가 매우 크긴 하다. (하나의 qdisc당 4만개의 패킷을 홀딩할 수 있다.) 그러나 qdisc 소모를 모니터링 해봤을때 대게 1ms 이내로 수만개의 패킷이 다 전송 되는것을 확인할 수 있었다. 추후 qdisc로 인해 문제가 생기면 줄일 가치가 있을것 같지만, 일반적인 상황에서는 저만큼의 값은 괜찮다고 여겨진다.



답글 남기기