CPU가 메모리에 접근하는데는 생각보다 긴 시간이 필요하다
CPU는 매우 빠르게 작동한다. 내 노트북만 해도 CPU가 3Ghz 돌아가고 있다. 이는 초당 3 000 000 000번 동작한다는것을 뜻한다. CPU는 이렇게 빠르지만 메모리는 그렇지 못하다. 물론 메모리가 HDD, SSD등 보다는 빠르다. 하지만 저 속도에는 못따라 가고 있다.
몇가지 실제 자료를 찾아봤는데 (7-cpu.com – 인텔 Skylake 메모리 속도, Redhat – Reducing Memory Access Times with Caches) 어쨋든 CPU에 비해서 많~~이 느리다. Redhat에 따르면 CPU는 0.5ns에 하나의 연산을 하는데 CPU가 메모리를 받아오려면 50ns가 걸린다고 한다. 단순 계산시 100배 차이 수준이다. (물론, 대역폭과 상황에 따라서 달라질 수 있다)
7-cpu의 자료에 따르면 봐도 메모리를 읽으려면 42개의 CPU 처리(사이클)와 51ns가 추가로 걸린다고 한다. L1 캐시 메모리는 4사이클(복잡한 주소 계신시 5사이클), L2 캐시에는 12사이클, L3 캐시에서는 38~42 사이클내로 가능하다는것과 크게 차이난다. (마찬가지로 대역폭과 상황에 따라서 달라질 수 있다)
어쨋든 하고픈 말은, CPU에서 메인 메모리를 접근하는것은 생각보다 느리다는것이다. 이게 아무것도 아니라고 보일수도 있다. 그러나 메인 메모리로의 접근 횟수와 비례해서 차이가 벌어진다. 조금의 CPU라도 아까운 대용량 처리 시스템에서는 아까울 수 밖에 없다. 특히 특수한 조건에서는 2배 이상의 속도 차이를 보여주기도 한다. 메모리를 많이 접근하는 프로그램일수록 더욱 크게 차이날 수도 있다.
결과적으로는 메모리를 어떻게 해야 더 빠르게 쓸 수 있냐? 라는 물음이 나오게 된다. 알고리즘·코드단에서 메모리 접근자체를 줄일수 있다면 좋겠지만.. 솔직히 쉽지 않다. 그렇다면 메모리를 접근하는 방법을 바꿔보는것은 어떨까? 그런점에서 나온것이 AoS(Array of Struct, Struct들을 Array로 묶은것)와 SoA(Struct of Array, Struct내에 Array를 두어서 데이터 저장)이다.
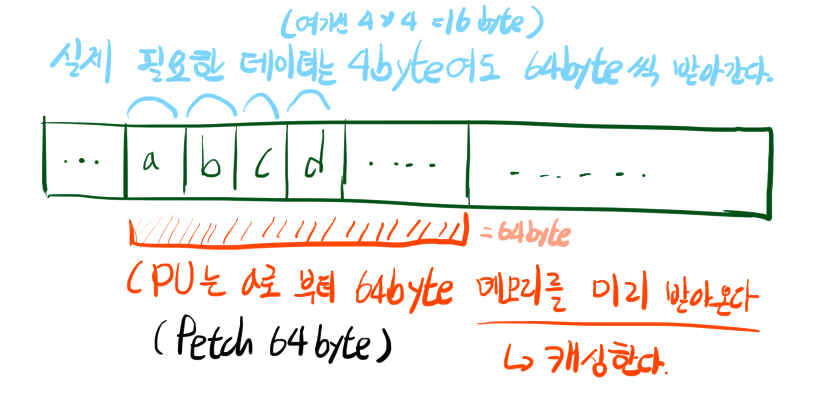
CPU는 한번에 64byte씩 읽는다
CPU는 메인 메모리를 읽으려면 상당한 시간이 걸린다는것을 알고있다. 캐시 메모리에서 데이터를 읽는것은 빠른 속도로 가능하다는것도 알고있다. 빠르게 작동하려면 필요한 메모리 영역을 통째로 CPU내의 캐시 메모리에 올려놓는것이 매우 중요하다는것을 아는것이다.
매 변수를 읽고 쓸때마다 메모리에 접근하는것은 비효율적이기에, CPU는 한번에 64byte씩 메모리를 접근해서 캐시 메모리에 올려둔다. a라는 변수를 읽으면 그 뒤에 있는 데이터도 접근하겠지? 라는 기대를 안고 a변수 부터 해서 64바이트를 통으로 접근하고 캐싱하는 것이다.
int main() {
int a, b, c, d;
a = 1;
b = 2;
c = 3;
d = 4;
}위와 같은 프로그램이 있다고 생각해 보자. a = 1 이라는 코드가 실행되면 이미 CPU에서는 b, c, d 에 대한 메모리를 읽어온 상태이다. CPU <-> 메모리 사이 통신이 비교적 느리다보니 64byte씩 미리 불러와서 캐싱하니 생기는 일이다. 실제 필요한 데이터가 4byte라고 해도 시작 지점으로 부터 64byte를 캐싱한다. 그 뒤에 무슨 데이터가 있던간에(아무런 데이터가 없더라도!) 일단 64byte씩 캐싱한다.
Struct of Array, Array of Struct
위의 개념에서 이어진다. 필요한 데이터들을 모아서 저장한다면 메모리 캐시를 효율적으로 (무수한 Hit 세례가!) 사용할 수 있지 않을까? 라는 생각인 것이다.
struct Server {
int server_id;
int tx_bytes;
int rx_bytes;
int conn;
char padding[48];
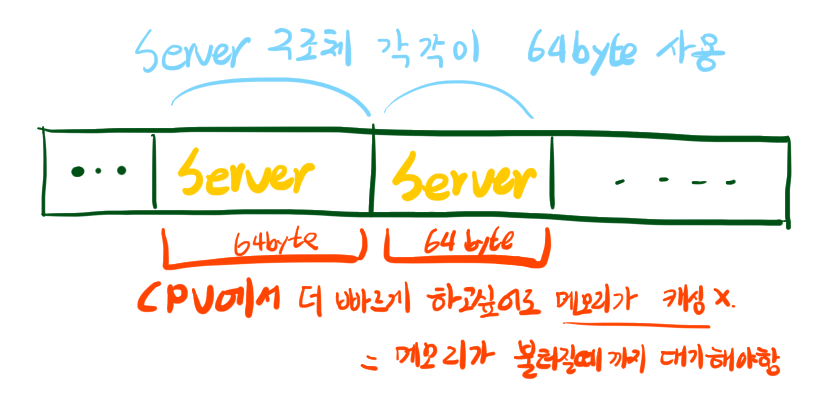
}위와 같은 구조체가 있다고 생각해 보자. 이 구조체는 극단적인 예를 들기위해서 64byte를 가지도록 만들었다. 이 Server 구조체를 배열에 수천개, 수만개 저장한다고 생각해 보자. CPU입장에서는 Server 구조체를 접근할 때 마다 새로 메모리를 캐싱해야 할 것이다. 이걸 한번 읽으면 64 바이트가 꽉 차기 때문이다.
그렇다면 Server 구조체를 배열에 저장하는게 아니라, Server의 각 필드를 배열로 저장하면 어떨까? 각 필드마다 연속적으로 저장되어 있기에 필드를 순차적으로 접근한다면 보다 나은 속도를 기대할 수 있다.
struct Server {
int* server_id = malloc(sizeof(int) * 1024);
int* tx_bytes = malloc(sizeof(int) * 1024);
int* rx_bytes = malloc(sizeof(int) * 1024);
int* conn = malloc(sizeof(int) * 1024);
}
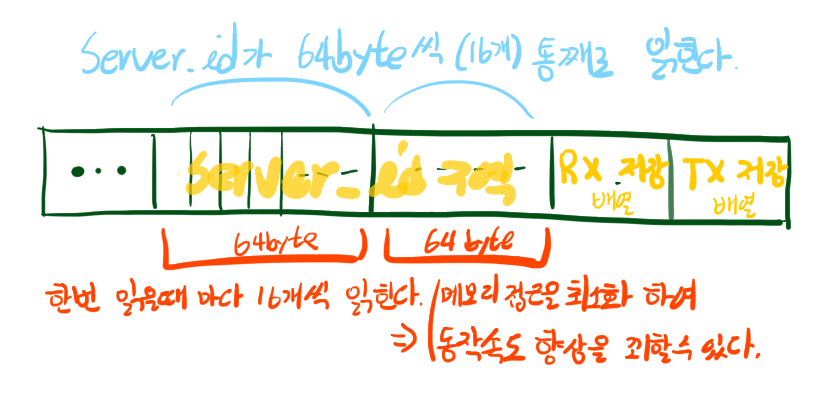
// Pseudo 코드로 작성해 보았다. Struct이 Array를 담고 있다.예를 들어, 특정 server_id가 배열에 있는지 확인하는 작업을 한다고 해보자. 기존 코드에서는 메모리 캐싱이 struct 1개만 저장하면 꽉 차서 매번 struct을 읽기 위해 메모리를 기다려야 했다. 하지만 이제는 server_id를 16개씩(캐시크기 / int 크기 = 64 / 4) 캐싱할 수 있게되어 저번 보다 더욱 효율적으로 메모리 접근이 가능해 졌다. 단순히 생각해서 메모리를 읽는데 1초가 걸린다고 하자. server_id를 16개 읽을때 구조체가 모여있는 배열에서 조회할 때는 16초가 걸린다. 하지만 구조체에서 각 필드를 저장하는 배열속에서 조회할 때는 1초면 된다. (여러 Optimization을 생략했다)
사실 둘 중 뭐가 더 좋다라고 할 수는 없다. 아래에서 보겠지만 AoS (=Array of Struct)가 유리한 구조가 있고 SoA (=Struct of Array)가 유리한 구조가 있다. 프로그램의 구조에 따라서 같이 쓰는 변수들의 메모리 공간을 모아두면 프로그램을 보더 더 빨리 돌릴수 있다는게 핵심이다. 바로 최인접은 안되더라도 64byte내에 존재하면 될 것이다.
속도를 실측해 보자!
실제 속도를 측정해 보았다. 테스트는 메모리 구조가 하드웨어에 직관적으로 그려지는 C언어로 진행했다. 모두 리눅스(라이젠7 4750U, 메모리 16GB, 하모니카 ME, 커널 5.8.9)에서 gcc로 -O3 옵션을 통해 (GCC 버전 Ubuntu 7.5.0-3ubuntu1~18.04) 컴파일 및 실행 하였다. 테스트는 번갈아가며 각 3회씩 실시하였고, 각 테스트마다 1초씩 sleep을 부여하였다.
테스트 케이스 1
struct내의 tx와 rx를 접근하는 상황을 그려보았다.
// AOS, ESukmean
#include <stdlib.h>
#include <stdio.h>
#include <time.h>
typedef struct server {
unsigned long server_id; //8-byte
unsigned long tx; //8-byte
unsigned long rx; //8-byte
unsigned long conn; // 8-byte
} Server;
inline long rnd(){
return rand();
}
void assign(Server* list, int size) {
for(int i = 0; i < size; i++) {
list[i].conn = i;
list[i].rx = rnd();
list[i].tx = rnd();
list[i].conn = rnd();
}
}
int main(int argc, char* argv[]) {
int size = atoi(argv[1]);
Server* list = malloc(sizeof(Server) * size);
assign(list, size);
unsigned long long sum = 0;
unsigned long max = 0;
clock_t end;
clock_t start = clock();
for(int i = 0; i < size; i++){
sum = list[i].tx + list[i].rx;
}
end = clock();
printf("%d -> %ld ms ==> %lld", size, end - start, sum);
}// SOA, ESukmean
#include <stdlib.h>
#include <stdio.h>
#include <time.h>
typedef struct server {
unsigned long* server_id;
unsigned long* tx;
unsigned long* rx;
unsigned long* conn;
} Server;
inline long rnd(){
return rand();
}
void assign(Server* list, int size) {
for(int i = 0; i < size; i++) {
list->conn[i] = i;
list->rx[i] = rnd();
list->tx[i] = rnd();
list->conn[i] = rnd();
}
}
int main(int argc, char* argv[]) {
int size = atoi(argv[1]);
Server list;
list.server_id = malloc(sizeof(unsigned long) * size);
list.tx = malloc(sizeof(unsigned long) * size);
list.rx = malloc(sizeof(unsigned long) * size);
list.conn = malloc(sizeof(unsigned long) * size);
assign(&list, size);
unsigned long long sum = 0;
unsigned long max = 0;
clock_t end;
clock_t start = clock();
for(int i = 0; i < size; i++){
sum = list.tx[i] + list.rx[i];
}
end = clock();
printf("%d -> %ld ms ==> %lld", size, end - start, sum);
}결과는 SoA가 AoS보다 2.2배 정도 빠르게 나왔다.
SoA – (Struct내에 Array를 여러개 둘 경우)일때의 결과:
| 배열의 크기 | 1회 (ms) | 2회 (ms) | 3회 (ms) | 실행 평균 (ms) |
|---|---|---|---|---|
| 1 | 2 | 3 | 2 | 2.3 |
| 2 | 2 | 2 | 4 | 2.7 |
| 4 | 2 | 2 | 2 | 2.0 |
| 8 | 2 | 2 | 2 | 2.0 |
| 16 | 2 | 3 | 2 | 2.3 |
| 32 | 1 | 2 | 2 | 1.7 |
| 64 | 2 | 2 | 1 | 1.7 |
| 128 | 1 | 2 | 1 | 1.3 |
| 256 | 1 | 3 | 3 | 2.3 |
| 512 | 2 | 2 | 2 | 2.0 |
| 1024 | 3 | 3 | 3 | 3.0 |
| 2048 | 4 | 4 | 4 | 4.0 |
| 4096 | 5 | 5 | 5 | 5.0 |
| 8192 | 6 | 8 | 8 | 7.3 |
| 16384 | 17 | 15 | 16 | 16.0 |
| 32768 | 29 | 30 | 30 | 29.7 |
| 65536 | 54 | 52 | 52 | 52.7 |
| 131072 | 99 | 114 | 118 | 110.3 |
| 262144 | 238 | 234 | 213 | 228.3 |
| 524288 | 421 | 401 | 437 | 419.7 |
| 1048576 | 793 | 825 | 744 | 787.3 |
| 2097152 | 1420 | 1403 | 1433 | 1,418.7 |
| 4194304 | 2689 | 2897 | 2955 | 2,847.0 |
| 8388608 | 5766 | 5738 | 5498 | 5,667.3 |
| 16777216 | 13745 | 13974 | 13842 | 13,853.7 |
| 33554432 | 26709 | 26588 | 26688 | 26,661.7 |
| 67108864 | 53840 | 54313 | 54190 | 54,114.3 |
| 134217728 | 108667 | 110983 | 108770 | 109,473.3 |
| 268435456 | 219824 | 219360 | 218956 | 219,380.0 |
AoS – (Array를 만들고 그 안에 Struct을 담는 방식) 일때의 결과:
| 배열의 크기 | 1회 (ms) | 2회 (ms) | 3회 (ms) | 실행 평균 (ms) |
|---|---|---|---|---|
| 1 | 3 | 3 | 3 | 3.0 |
| 2 | 2 | 1 | 2 | 1.7 |
| 4 | 2 | 2 | 3 | 2.3 |
| 8 | 2 | 3 | 3 | 2.7 |
| 16 | 2 | 2 | 3 | 2.3 |
| 32 | 2 | 2 | 2 | 2.0 |
| 64 | 1 | 3 | 2 | 2.0 |
| 128 | 2 | 3 | 2 | 2.3 |
| 256 | 2 | 2 | 3 | 2.3 |
| 512 | 2 | 3 | 2 | 2.3 |
| 1024 | 4 | 3 | 4 | 3.7 |
| 2048 | 4 | 6 | 5 | 5.0 |
| 4096 | 7 | 8 | 8 | 7.7 |
| 8192 | 14 | 15 | 14 | 14.3 |
| 16384 | 28 | 27 | 27 | 27.3 |
| 32768 | 52 | 45 | 68 | 55.0 |
| 65536 | 124 | 117 | 150 | 130.3 |
| 131072 | 314 | 317 | 280 | 303.7 |
| 262144 | 706 | 593 | 526 | 608.3 |
| 524288 | 1047 | 1063 | 1190 | 1,100.0 |
| 1048576 | 2031 | 2061 | 1815 | 1,969.0 |
| 2097152 | 3728 | 3720 | 3707 | 3,718.3 |
| 4194304 | 7064 | 7136 | 6908 | 7,036.0 |
| 8388608 | 14093 | 14125 | 14061 | 14,093.0 |
| 16777216 | 27279 | 27188 | 27458 | 27,308.3 |
| 33554432 | 56105 | 56030 | 56370 | 56,168.3 |
| 67108864 | 109954 | 113090 | 113524 | 112,189.3 |
| 134217728 | 226385 | 220107 | 225664 | 224,052.0 |
| 268435456 | 450575 | 452140 | 444382 | 449,032.3 |
테스트 케이스 2
이번에는 여러 데이터를 비교해 봐야하는 경우로 예제를 만들어 보았다. 예제로 만든것이어서 따로 integer overflow등은 고려하지 않았다. (경험상 각 서버의 사용 리소스 총 합을 구하는 경우가 많아서 꾸역꾸역 집어넣었다.)
// SOA, ESukmean
#include <stdlib.h>
#include <stdio.h>
#include <time.h>
typedef struct server {
unsigned long* server_id;
unsigned long* tx;
unsigned long* rx;
unsigned long* conn;
} Server;
inline long rnd(){
return rand() >> 1;
}
void assign(Server* list, int size) {
for(int i = 0; i < size; i++) {
list->conn[i] = i;
list->rx[i] = rnd();
list->tx[i] = rnd();
list->conn[i] = rnd();
}
}
int main(int argc, char* argv[]) {
int size = atoi(argv[1]);
Server list;
list.server_id = malloc(sizeof(unsigned long) * size);
list.tx = malloc(sizeof(unsigned long) * size);
list.rx = malloc(sizeof(unsigned long) * size);
list.conn = malloc(sizeof(unsigned long) * size);
assign(&list, size);
unsigned long long sum = 0;
unsigned long max = 0;
clock_t end;
// rnd()는 2^31까지만 표현함. 찾는값이 100% 없을테니 배열 전체를 탐색해야함.
unsigned long find_sid = ~0;
unsigned long max_tx = 0;
unsigned long max_rx = 0;
clock_t start = clock();
for(int i = 0; i < size; i++){
if (list.server_id[i] == find_sid) break;
}
for(int i = 0; i < size; i++){
if (list.tx[i] > max_tx) max_tx = list.tx[i];
}
for(int i = 0; i < size; i++){
if (list.tx[i] > max_rx) max_rx = list.tx[i];
}
end = clock();
printf("%d -> %ld ms ==> %ld", size, end - start, find_sid + max_tx + max_tx);
}// AOS, ESukmean
#include <stdlib.h>
#include <stdio.h>
#include <time.h>
typedef struct server {
unsigned long server_id; //8-byte
unsigned long tx; //8-byte
unsigned long rx; //8-byte
unsigned long conn; // 8-byte
} Server;
inline long rnd(){
return rand() >> 1;
}
void assign(Server* list, int size) {
for(int i = 0; i < size; i++) {
list[i].conn = i;
list[i].rx = rnd();
list[i].tx = rnd();
list[i].conn = rnd();
}
}
int main(int argc, char* argv[]) {
int size = atoi(argv[1]);
Server* list = malloc(sizeof(Server) * size);
assign(list, size);
unsigned long max = 0;
clock_t end;
// rnd()는 2^31까지만 표현함. 찾는값이 100% 없을테니 배열 전체를 탐색해야함.
unsigned long find_sid = ~0;
unsigned long max_tx = 0;
unsigned long max_rx = 0;
clock_t start = clock();
for(int i = 0; i < size; i++){
if (list[i].server_id == find_sid) break;
}
for(int i = 0; i < size; i++){
if (list[i].tx > max_tx) max_tx = list[i].tx;
}
for(int i = 0; i < size; i++){
if (list[i].tx > max_rx) max_rx = list[i].tx;
}
end = clock();
printf("%d -> %ld ms ==> %ld", size, end - start, find_sid + max_tx + max_tx);
}for과 if문이 늘어난 만큼, 결과는 더더욱 벌어졌다.
SoA로 실행시
| 배열의 갯수 | 1회 실행 | 2회 실행 | 3회 실행 | 평균 실행시간 (ms) |
|---|---|---|---|---|
| 1 | 1 | 2 | 3 | 2.0 |
| 2 | 2 | 2 | 3 | 2.3 |
| 4 | 2 | 2 | 2 | 2.0 |
| 8 | 2 | 2 | 3 | 2.3 |
| 16 | 1 | 2 | 1 | 1.3 |
| 32 | 2 | 2 | 2 | 2.0 |
| 64 | 2 | 2 | 2 | 2.0 |
| 128 | 2 | 2 | 2 | 2.0 |
| 256 | 2 | 2 | 2 | 2.0 |
| 512 | 2 | 2 | 3 | 2.3 |
| 1024 | 4 | 3 | 3 | 3.3 |
| 2048 | 6 | 6 | 5 | 5.7 |
| 4096 | 9 | 8 | 9 | 8.7 |
| 8192 | 15 | 14 | 12 | 13.7 |
| 16384 | 27 | 25 | 28 | 26.7 |
| 32768 | 49 | 49 | 45 | 47.7 |
| 65536 | 89 | 100 | 104 | 97.7 |
| 131072 | 177 | 181 | 78 | 145.3 |
| 262144 | 375 | 153 | 346 | 291.3 |
| 524288 | 388 | 383 | 374 | 381.7 |
| 1048576 | 653 | 705 | 807 | 721.7 |
| 2097152 | 1349 | 1315 | 1427 | 1,363.7 |
| 4194304 | 2705 | 2717 | 2772 | 2,731.3 |
| 8388608 | 5222 | 5164 | 5098 | 5,161.3 |
| 16777216 | 10163 | 10255 | 10222 | 10,213.3 |
| 33554432 | 20839 | 20516 | 20285 | 20,546.7 |
| 67108864 | 40349 | 40625 | 40192 | 40,388.7 |
| 134217728 | 80114 | 80053 | 80507 | 80,224.7 |
| 268435456 | 159693 | 160088 | 160033 | 159,938.0 |
AoS로 실행시
| 배열 크기 | 1회 실행 | 2회 실행 | 3회 실행 | 평균 실행시간 (ms) |
|---|---|---|---|---|
| 1 | 3 | 3 | 3 | 3.0 |
| 2 | 2 | 2 | 2 | 2.0 |
| 4 | 2 | 3 | 2 | 2.3 |
| 8 | 2 | 1 | 2 | 1.7 |
| 16 | 2 | 2 | 2 | 2.0 |
| 32 | 2 | 2 | 2 | 2.0 |
| 64 | 2 | 1 | 2 | 1.7 |
| 128 | 2 | 2 | 3 | 2.3 |
| 256 | 2 | 2 | 1 | 1.7 |
| 512 | 3 | 2 | 2 | 2.3 |
| 1024 | 3 | 4 | 3 | 3.3 |
| 2048 | 6 | 4 | 4 | 4.7 |
| 4096 | 7 | 7 | 8 | 7.3 |
| 8192 | 15 | 14 | 13 | 14.0 |
| 16384 | 22 | 27 | 25 | 24.7 |
| 32768 | 45 | 43 | 44 | 44.0 |
| 65536 | 107 | 104 | 120 | 110.3 |
| 131072 | 229 | 293 | 227 | 249.7 |
| 262144 | 560 | 547 | 570 | 559.0 |
| 524288 | 1020 | 1113 | 1047 | 1,060.0 |
| 1048576 | 2006 | 1857 | 1991 | 1,951.3 |
| 2097152 | 3706 | 3627 | 3632 | 3,655.0 |
| 4194304 | 6997 | 7080 | 7109 | 7,062.0 |
| 8388608 | 13628 | 14093 | 13738 | 13,819.7 |
| 16777216 | 27326 | 26985 | 27667 | 27,326.0 |
| 33554432 | 55055 | 55245 | 55263 | 55,187.7 |
| 67108864 | 111401 | 110261 | 110215 | 110,625.7 |
| 134217728 | 221639 | 221538 | 224644 | 222,607.0 |
| 268435456 | 435305 | 446244 | 443533 | 441,694.0 |
최적화 옵션을 다르게 하면?
위의 코드는 -O3 옵션으로 컴파일 했을때의 결과이다. -O3에는 Auto Vectorization등의 옵션이 섞여 있어서 CPU캐싱만 보기에는 조금 애매하다. 컴파일러가 개입할 수 있는 상황이라면 위와 같은 추세로 실행시간이 나오겠지만, 그렇지 않다면 얼마나 차이날까? 그래서 -O0로 배열 크기가 268,435,456일때를 기준으로 빠르게 돌려보았다.
테스트 케이스 1: AoS 725347ms, SoA 671128ms
테스트 케이스 2: AoS 2578004ms, SoA 1670109ms
결론
여러 상황과 구조에 따라서 적합한 메모리 구조는 다를 수 있다. 적절한 메모리 구조를 사용하는것은 그렇지 않을때와 비교했을때 위와같이 큰 차이를 만들수도 있다. 특히 대용량 처리 시스템이거나 상당한 양의 메모리를 접근해야 할 때 자신의 코드를 열어보고 좀 더 적합한 – 캐시 히트율이 높은 – 방법을 찾아보자.
후기
사실 테스트 케이스1은 AoS(Array속에 Struct을 저장하는식)이 더 나을것이라 생각했습니다. SoA으로 접근하려면 두개의 배열을 번갈아가며 읽어야 하니까 오히려 비효율적일것이라 생각했습니다. 근데 결과를 보니까 제 추측이 틀렸네요. 한번에 저장하는 캐시의 크기는 64kb이지만 8개의 캐시 라인을 가지고 있는 만큼, 두 배열 모두 캐싱이 된 것 같습니다. 두 배열 모두 캐싱이 되었다면 더 빠르겠네요.
테스트 케이스1에서 결과가 이상해서 혹시나 GCC의 -O3 플레그가 영향을 끼치지 않았을까? 생각이 들었습니다. -O3 플레그를 빼고 컴파일을 해도 결과는 둘 다 시간이 늘었긴 하지만 추세는 비슷하다는것을 확인할 수 있었습니다. 한편, -O3가 적용이 되면 GCC에서 자동 벡터라이징 (SIMD화)을 진행하기에 SoA에서 더욱 파워풀한 컴퓨팅을 느낄 수도 있을겁니다.
AoS와 SoA모두 적합한 케이스가 따로있을거라 봤는데.. 왠만해선 SoA가 더 나을것 같다~ 가 제 결론입니다.
C, C++, Rust등이 아닌 다른언어에서는 데이터가 넓게넓게 퍼저있을 가능성이 있습니다. 이것들을 제대로 사용하고 싶으면 저 수준의 언어를 사용하는것이 더 효과적일것이라 생각합니다.

답글 남기기