저번 글에서 AoS와 SoA의 개념에 대해 글을 써 보았다. AoS와 SoA 이야기를 논하려면 데이터가 메모리에 가지런히 모여있다는 전재를 해야한다. 배열을 만들었으나 실제로는 데이터가 연속적으로 모여있지 않고 뿔뿔히 흩어저 있으면 메모리 캐싱이 될 리가 만무하다. 즉, AoS와 SoA는 메모리 구조가 시스템적일수록 더욱 효율적으로 동작한다. 배열의 저장과 그 외 기능의 동작이 군더더기 없이 딱 필요한 기능만 동작될 때 (언어의 개입이 적을수록) 속도가 더 빨라질수 밖에 없는거다.
AoS와 SoA가 뭔지 모르는 사람을 위해 간략하게 설명하자면… 메모리는 1차원적인 구조로 데이터를 읽고 쓴다. Struct을 만들어 저장한다면 메모리를 들여다 봤을때 가로 방향으로 순서대로 저장되어 있는것을 볼 수 있다. 2차원, 3차원 배열을 만들어도 실제로는 가로로 1차원적으로 저장된다. 이 때 개발자가 조금만 더 신경을 쓴다면 데이터를 가로로 나열할 기준을 정할 수 있다. AoS는 Struct을 덩어리로 하여금 데이터를 가로로 나열한다. SoA는 실제 저장되는 데이터를 가로로 나열한다.
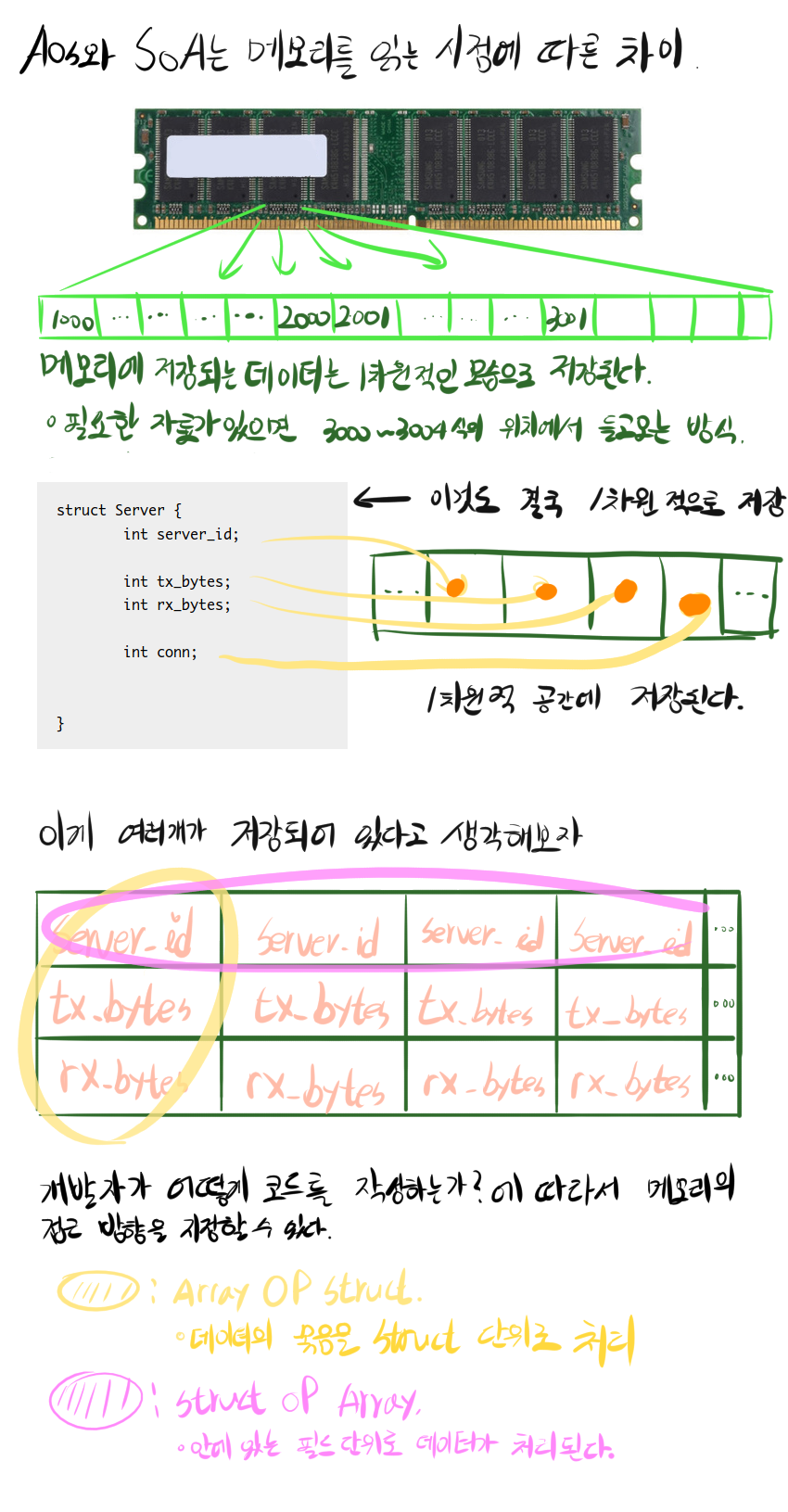
메모리 구조를 살펴보면 차이점이 보인다. 위에서 말했듯이 AoS는 Struct을 한 그룹으로 저장한다. SoA는 각 필드를 그룹으로 하여 저장한다. 아래의 그림을 보면 더 잘 이해된다. CPU는 메모리를 읽을때 64byte씩 읽고나서 CPU 내부의 캐시공간에 둔다. 메모리를 읽고 쓰는건 CPU 기준에서는 느린 작업임으로 한번에 뭉탱이로 읽고나서 “뒤에서도 쓰이겠지 ㅎ” 라는 생각으로 캐싱을 하는 것이다.
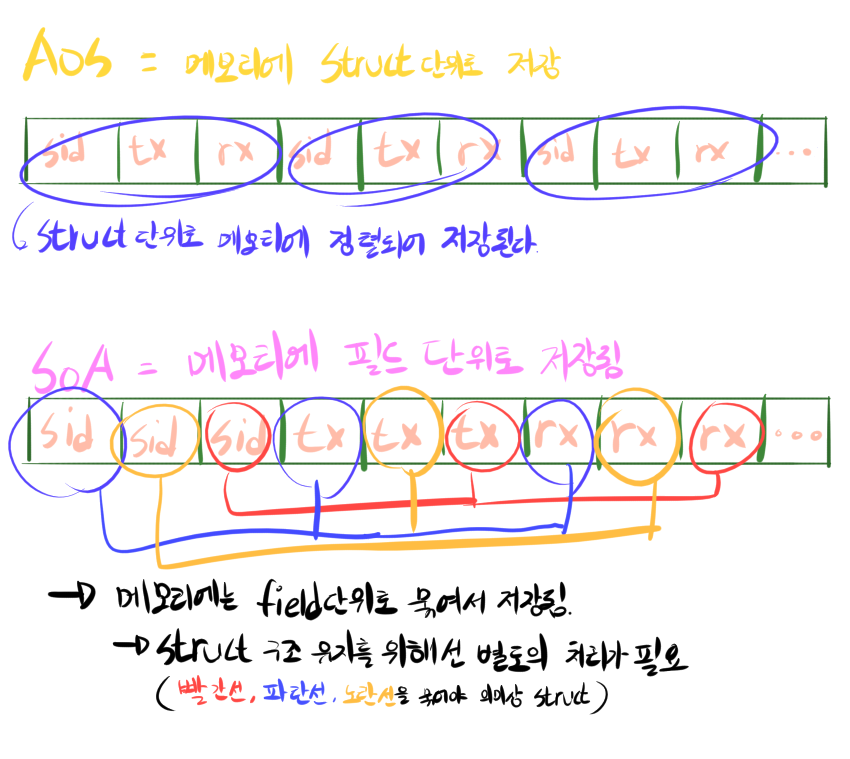
맨 첫문단에서도 설명했듯이 CPU의 메모리 캐시 기능을 통해 잃어버린 속도를 되찾는것이 목적이다. 즉, 한번 읽을때 필요한 데이터가 CPU 캐시 공간에 최대한 많이 들어가게 하는것이 목적인 것이다. 그런데… 만약 프로그램이 이걸 일렬적이지 않고 아무때나 흩뿌려서 저장을 하면 아무리 CPU 캐시를 쓰고싶어도 다음 데이터가 캐시 공간에 올라가지 못한다. 하나의 캐시는 64byte 라는 조건이 있기에 효율적으로 캐시에 올리는것이 중요하다.
그래서 이번에는 언어별 SoA AoS 속도 차이를 비교해 보려한다. C++이나 C나 Rust같이 시스템 메모리 구조를 그대로 가지고 가는 언어에서는 실질적으로 아무 차이 없음으로 측정하지 않았다. 여기서는 메모리 구조를 시스템과 다르게 저장할 수도 있는 언어 몇가지만 측정해 보았다
언어별 SoA AoS 속도 측정 (퍼포먼스 측정)
여기서의 코드는 상당히 단편적인 부분만을 다룬다. 실제 개발하는 프로그램에서는 다른 결과를 보여줄 수 있다. 상황에 따라 올바른 구조를 파악하는것이 중요하다.
모든 테스트는 내 노트북 (AMD Ryzen 4750U, 16GB DDR4, 하모니카OS, Linux esukmean-latop 5.8.9-050809-generic #202009120936 SMP Sat Sep 12 13:59:35 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux)에서 이루어졌다. 배열 크기가 바뀔 때 마다 1초씩 텀을 주었다. 실험은 총 3 x 4회 실시하였으나 첫번째 결과만 첨부한다. (짜피 추세는 일치한다)
Java
openjdk version "11.0.8" 2020-07-14
OpenJDK Runtime Environment (build 11.0.8+10-post-Ubuntu-0ubuntu118.04.1)
OpenJDK 64-Bit Server VM (build 11.0.8+10-post-Ubuntu-0ubuntu118.04.1, mixed mode, sharing)// SOA.java
import java.util.Random;
public class soa {
public static void main(String[] args) {
int size = Integer.parseInt(args[0]);
server list = new server(size);
list.fill();
long sum_tx = 0;
long sum_rx = 0;
long start = System.currentTimeMillis();
for (int i = 0; i < list.tx.length; i++) {
sum_tx += list.tx[i];
sum_rx += list.rx[i];
}
long end = System.currentTimeMillis();
System.out.print(size + " => " + (end - start) + " | " + (sum_tx + sum_rx));
}
}
class server {
int server_id[];
int tx[];
int rx[];
int conn[];
public server(int size) {
this.server_id = new int[size];
this.tx = new int[size];
this.rx = new int[size];
this.conn = new int[size];
}
public void fill() {
Random rnd = new Random();
for(int i = 0; i < this.server_id.length; i++){
this.server_id[i] = rnd.nextInt();
this.tx[i] = rnd.nextInt();
this.rx[i] = rnd.nextInt();
this.conn[i] = rnd.nextInt();
}
}
}// AOS.java
import java.util.Random;
public class aos {
public static void main(String[] args) {
int size = Integer.parseInt(args[0]);
server list[] = new server[size];
for (int i = 0; i < list.length; i++) {
list[i] = new server();
list[i].fill();
}
long sum_tx = 0;
long sum_rx = 0;
long start = System.currentTimeMillis();
for (int i = 0; i < list.length; i++) {
sum_tx += list[i].tx;
sum_rx += list[i].rx;
}
long end = System.currentTimeMillis();
System.out.print(size + " => " + (end - start) + " | " + (sum_tx + sum_rx));
}
}
class server {
int server_id;
int tx;
int rx;
int conn;
public void fill() {
Random rnd = new Random();
this.server_id = rnd.nextInt();
this.tx = rnd.nextInt();
this.rx = rnd.nextInt();
this.conn = rnd.nextInt();
}
}SOA 실행결과
| 배열크기 | 1회차 | 2회차 | 3회차 | 평균시간 (ms) |
|---|---|---|---|---|
| 1 | 0 | 0 | 0 | 0.0 |
| 2 | 0 | 0 | 0 | 0.0 |
| 4 | 0 | 0 | 0 | 0.0 |
| 8 | 0 | 0 | 0 | 0.0 |
| 16 | 0 | 0 | 0 | 0.0 |
| 32 | 0 | 0 | 0 | 0.0 |
| 64 | 0 | 0 | 0 | 0.0 |
| 128 | 0 | 0 | 0 | 0.0 |
| 256 | 0 | 0 | 0 | 0.0 |
| 512 | 0 | 0 | 0 | 0.0 |
| 1024 | 0 | 0 | 0 | 0.0 |
| 2048 | 0 | 0 | 0 | 0.0 |
| 4096 | 0 | 0 | 0 | 0.0 |
| 8192 | 0 | 0 | 0 | 0.0 |
| 16384 | 1 | 1 | 0 | 0.7 |
| 32768 | 1 | 1 | 1 | 1.0 |
| 65536 | 2 | 1 | 2 | 1.7 |
| 131072 | 3 | 3 | 3 | 3.0 |
| 262144 | 3 | 4 | 6 | 4.3 |
| 524288 | 4 | 4 | 4 | 4.0 |
| 1048576 | 6 | 5 | 5 | 5.3 |
| 2097152 | 8 | 8 | 8 | 8.0 |
| 4194304 | 13 | 10 | 11 | 11.3 |
| 8388608 | 14 | 12 | 12 | 12.7 |
| 16777216 | 16 | 17 | 17 | 16.7 |
| 33554432 | 25 | 28 | 25 | 26.0 |
AOS 실행결과
| 배열 크기 | 1회차 | 2회차 | 3회차 | 평균시간 (ms) |
|---|---|---|---|---|
| 1 | 0 | 0 | 0 | 0.0 |
| 2 | 0 | 0 | 0 | 0.0 |
| 4 | 0 | 0 | 0 | 0.0 |
| 8 | 0 | 0 | 0 | 0.0 |
| 16 | 0 | 0 | 0 | 0.0 |
| 32 | 0 | 0 | 0 | 0.0 |
| 64 | 0 | 0 | 0 | 0.0 |
| 128 | 0 | 0 | 0 | 0.0 |
| 256 | 0 | 0 | 0 | 0.0 |
| 512 | 0 | 0 | 0 | 0.0 |
| 1024 | 0 | 0 | 0 | 0.0 |
| 2048 | 0 | 0 | 0 | 0.0 |
| 4096 | 1 | 0 | 0 | 0.3 |
| 8192 | 0 | 1 | 1 | 0.7 |
| 16384 | 1 | 1 | 1 | 1.0 |
| 32768 | 1 | 1 | 1 | 1.0 |
| 65536 | 0 | 1 | 0 | 0.3 |
| 131072 | 2 | 2 | 1 | 1.7 |
| 262144 | 2 | 2 | 3 | 2.3 |
| 524288 | 3 | 3 | 3 | 3.0 |
| 1048576 | 6 | 7 | 5 | 6.0 |
| 2097152 | 10 | 10 | 10 | 10.0 |
| 4194304 | 14 | 16 | 15 | 15.0 |
| 8388608 | 25 | 25 | 24 | 24.7 |
| 16777216 | 44 | 42 | 44 | 43.3 |
| 33554432 | 82 | 81 | 81 | 81.3 |
초반에는 별 차이가 없다가 배열이 많이 커지는 순간부터 상당한 시간 격차를 보여준다. 사실 이 코드는 SoA에 좀 더 친화적으로 짜여있다. CPU 캐시 공간에는 동시에 10개 이상의 캐시를 보관할 수 있다. 접근하는 Struct의 필드가 많아지면 아등바등한 결과를 보여주거나, 오히려 역전할 수 도 있다.
결과값이 최대 4배까지도 나는걸 보면.. 메모리 구조가 지금같은 특수한 상황을 인식해서 상당한 수준의 최적화가 내부에서 발생한 것 같다. 자바 컴파일러가 자동으로 vectorization을 지원한다고 하니까 여기서도 해당 최적화가 개입한 게 아닐까 생각해 본다.
Python3 (CPython 3.6.9)
// SOA.py
import time
import sys
import random
def rnd():
return int(random.random() * 10000000)
class server:
server_id = []
tx = []
rx = []
conn = []
def __init__(self, size):
self.server_id = [0] * size
self.tx = [0] * size
self.rx = [0] * size
self.conn = [0] * size
def fill(self, pos):
self.server_id[pos] = rnd()
self.tx[pos] = rnd()
self.rx[pos] = rnd()
self.conn[pos] = rnd()
size = int(sys.argv[1])
slist = server(size)
for i in range(size):
slist.fill(i)
sum_tx = 0
sum_rx = 0
start = time.time()
for i in range(size):
sum_tx += slist.tx[i]
sum_rx += slist.rx[i]
end = time.time()
print('{} => {} | {}'.format(size, int((end - start) * 1000), sum_rx + sum_tx), end='')// AOS.py
import time
import sys
import random
def rnd():
return int(random.random() * 10000000)
class server:
server_id = 0
tx = 0
rx = 0
conn = 0
def __init__(self):
pass
def fill(self):
self.server_id = rnd()
self.tx = rnd()
self.rx = rnd()
self.conn = rnd()
size = int(sys.argv[1])
slist = size * [server]
for i in range(size):
slist[i] = server()
slist[i].fill()
sum_tx = 0
sum_rx = 0
start = time.time()
for i in range(size):
sum_tx += slist[i].tx
sum_rx += slist[i].rx
end = time.time()
print('{} => {} | {}'.format(size, int((end - start) * 1000), sum_rx + sum_tx), end='')SOA 실행 결과
| 배열 크기 | 1회차 | 2회차 | 3회차 | 평균 시간(ms) |
|---|---|---|---|---|
| 1 | 0 | 0 | 0 | 0.0 |
| 2 | 0 | 0 | 0 | 0.0 |
| 4 | 0 | 0 | 0 | 0.0 |
| 8 | 0 | 0 | 0 | 0.0 |
| 16 | 0 | 0 | 0 | 0.0 |
| 32 | 0 | 0 | 0 | 0.0 |
| 64 | 0 | 0 | 0 | 0.0 |
| 128 | 0 | 0 | 0 | 0.0 |
| 256 | 0 | 0 | 0 | 0.0 |
| 512 | 0 | 0 | 0 | 0.0 |
| 1024 | 0 | 0 | 0 | 0.0 |
| 2048 | 0 | 0 | 0 | 0.0 |
| 4096 | 0 | 0 | 0 | 0.0 |
| 8192 | 1 | 1 | 1 | 1.0 |
| 16384 | 3 | 3 | 3 | 3.0 |
| 32768 | 5 | 5 | 5 | 5.0 |
| 65536 | 12 | 12 | 14 | 12.7 |
| 131072 | 22 | 25 | 22 | 23.0 |
| 262144 | 55 | 49 | 48 | 50.7 |
| 524288 | 84 | 89 | 97 | 90.0 |
| 1048576 | 228 | 189 | 180 | 199.0 |
| 2097152 | 436 | 356 | 368 | 386.7 |
| 4194304 | 786 | 775 | 784 | 781.7 |
| 8388608 | 1572 | 1436 | 1478 | 1495.3 |
| 16777216 | 2956 | 2890 | 2946 | 2930.7 |
| 33554432 | 6327 | 5764 | 6290 | 6127.0 |
AOS 실행결과
| 배열크기 | 1회차 | 2회차 | 3회차 | 평균시간 |
|---|---|---|---|---|
| 1 | 0 | 0 | 0 | 0.0 |
| 2 | 0 | 0 | 0 | 0.0 |
| 4 | 0 | 0 | 0 | 0.0 |
| 8 | 0 | 0 | 0 | 0.0 |
| 16 | 0 | 0 | 0 | 0.0 |
| 32 | 0 | 0 | 0 | 0.0 |
| 64 | 0 | 0 | 0 | 0.0 |
| 128 | 0 | 0 | 0 | 0.0 |
| 256 | 0 | 0 | 0 | 0.0 |
| 512 | 0 | 0 | 0 | 0.0 |
| 1024 | 0 | 0 | 0 | 0.0 |
| 2048 | 0 | 0 | 0 | 0.0 |
| 4096 | 0 | 0 | 0 | 0.0 |
| 8192 | 1 | 1 | 1 | 1.0 |
| 16384 | 3 | 2 | 3 | 2.7 |
| 32768 | 6 | 5 | 6 | 5.7 |
| 65536 | 11 | 12 | 11 | 11.3 |
| 131072 | 25 | 23 | 24 | 24.0 |
| 262144 | 46 | 48 | 46 | 46.7 |
| 524288 | 87 | 101 | 89 | 92.3 |
| 1048576 | 183 | 219 | 192 | 198.0 |
| 2097152 | 368 | 410 | 367 | 381.7 |
| 4194304 | 761 | 772 | 743 | 758.7 |
| 8388608 | 1575 | 1480 | 1541 | 1532.0 |
| 16777216 | 3226 | 2952 | 2859 | 3012.3 |
| 33554432 | 5828 | 6372 | 6381 | 6193.7 |
Python3는 사실상 두개의 차이가 거의 없다고 보여진다. 아주 조금 차이가 있긴 하지만… 저정도면 없는거라고 봐도 무방할 것 같다. 이게 메모리 구조상의 차이인지 아니면 내부 구동 방식에 따른 차이인지는 모르겠다. 어쨋든 cPython에서는 별 차이 없는거로!
Pypy3
Python 3.6.9 (7.3.2+dfsg-2~ppa1~ubuntu18.04, Sep 26 2020, 22:38:00)
[PyPy 7.3.2 with GCC 7.5.0]코드는 윗 문단인 Python3의 것과 동일하다. 결과만 살펴보자.
SoA 실행시간
| 배열크기 | 1회차 | 2회차 | 3회차 | 평균 시간(ms) |
|---|---|---|---|---|
| 1 | 0 | 0 | 0 | 0.0 |
| 2 | 0 | 0 | 0 | 0.0 |
| 4 | 0 | 0 | 0 | 0.0 |
| 8 | 0 | 0 | 0 | 0.0 |
| 16 | 0 | 0 | 0 | 0.0 |
| 32 | 0 | 0 | 0 | 0.0 |
| 64 | 0 | 0 | 0 | 0.0 |
| 128 | 0 | 0 | 0 | 0.0 |
| 256 | 0 | 0 | 0 | 0.0 |
| 512 | 0 | 0 | 0 | 0.0 |
| 1024 | 0 | 0 | 0 | 0.0 |
| 2048 | 1 | 1 | 1 | 1.0 |
| 4096 | 1 | 1 | 1 | 1.0 |
| 8192 | 1 | 1 | 1 | 1.0 |
| 16384 | 1 | 1 | 1 | 1.0 |
| 32768 | 1 | 1 | 1 | 1.0 |
| 65536 | 1 | 1 | 1 | 1.0 |
| 131072 | 1 | 1 | 1 | 1.0 |
| 262144 | 2 | 1 | 1 | 1.3 |
| 524288 | 2 | 2 | 2 | 2.0 |
| 1048576 | 3 | 3 | 3 | 3.0 |
| 2097152 | 5 | 6 | 5 | 5.3 |
| 4194304 | 11 | 10 | 10 | 10.3 |
| 8388608 | 20 | 20 | 20 | 20.0 |
| 16777216 | 45 | 45 | 45 | 45.0 |
| 33554432 | 82 | 81 | 82 | 81.7 |
AoS 실행시간
| 1 | 0 | 0 | 0 | 0.0 |
| 2 | 0 | 0 | 0 | 0.0 |
| 4 | 0 | 0 | 0 | 0.0 |
| 8 | 0 | 0 | 0 | 0.0 |
| 16 | 0 | 0 | 0 | 0.0 |
| 32 | 0 | 0 | 0 | 0.0 |
| 64 | 0 | 0 | 0 | 0.0 |
| 128 | 0 | 0 | 0 | 0.0 |
| 256 | 0 | 0 | 0 | 0.0 |
| 512 | 0 | 0 | 0 | 0.0 |
| 1024 | 0 | 0 | 0 | 0.0 |
| 2048 | 1 | 1 | 1 | 1.0 |
| 4096 | 1 | 1 | 1 | 1.0 |
| 8192 | 1 | 1 | 1 | 1.0 |
| 16384 | 4 | 5 | 4 | 4.3 |
| 32768 | 1 | 1 | 1 | 1.0 |
| 65536 | 3 | 3 | 3 | 3.0 |
| 131072 | 5 | 6 | 5 | 5.3 |
| 262144 | 4 | 4 | 4 | 4.0 |
| 524288 | 6 | 5 | 5 | 5.3 |
| 1048576 | 13 | 11 | 11 | 11.7 |
| 2097152 | 17 | 18 | 17 | 17.3 |
| 4194304 | 28 | 28 | 28 | 28.0 |
| 8388608 | 54 | 77 | 53 | 61.3 |
| 16777216 | 109 | 109 | 108 | 108.7 |
| 33554432 | 216 | 214 | 215 | 215.0 |
결과를 보면 CPython3와의 속도 차이가 우선해서 보인다. 배열 크기가 2^25일때 기준으로 약 28배의 속도 차이를 보여준다. SoA일때는 무려 74배 가량의 속도 차이를 보여준다. 물론 이 코드는 실제 쓰이는 프로그램들과 차이가 있다. 그것을 감안하더라도 속도 차이가 상당히 발생한다는것을 볼 수 있다.
SoA와 AoS의 속도 자체만 비교해 보면 약 2.5배의 속도 차이를 볼 수 있다. pypy3가 조금 더 시스템적인 메모리 구조를 사용한다거나, 별도의 최적화가 구현되어 있음을 보여준다. 코드에 따라 다르겠지만 cpython이 아닌 pypy를 이용한다면 SoA를 적극적으로 검토해 볼 필요가 있을듯 하다.
Java와 마찬가지로 자동 vectorization를 지원한다니까.. 아무래도 SIMD까지 개입한 결과로 보인다. 위의 예제와 같은 구조로 코드를 바꿀수 있다면 결과값처럼 2.5배에 달하는 성능 향상을 꽤 할수 있을것이다.
결론
언어에 따른 차이가 분명 존재한다. 그럼에도 불구하고 python3같이 매우 고수준의 언어 구현을 제외하면 SoA가 더 빠른 경향을 보여주었다. 같은 언어에서도 구현에 따라 (Python3와 Pypy3) 경향이 바뀔수도 있다. 이는 메모리 구조와 기능 동작, 최적화가 구현에 따라 다르게 이루어저 있으며, 그에 따라 속도 차이가 발생할 수 있음을 보여준다. 당장의 결과값만 보면 배열이 커질수록 격차가 더 늘어남을 볼 수 있다. liner(선형적)하긴 하지만, 값이 커짐에 따라서 기울기가 더 커지는 경향을 보였다.
코드에 따라 결과는 다르게 나올수도 있다. Struct의 필드가 늘어나고 Struct내의 필드끼리의 계산이 많아지면 역전될 수도 있다. CPU 캐시 공간은 무한하지 않음으로, 필드가 많아지면 오히려 매 번 메모리 접근이 필요할 수도 있기 때문이다. CPU 캐시 공간에 따라 달라지는것이기에 CPU에 따라서 이 차이가 늘어날 수도, 줄어들 수도 있다.
타겟 CPU와 자신이 처한 상황속에서 어느것이 자신에게 더 적합한지 알아보는것이 중요할 것이다.
한편, SoA에서는 배열 여러개 끼리 인접하게 저장될 가능성이 매우 높다. server_id 배열 바로 뒤에 tx_bytes, 그 뒤에 바로 rx_bytes 배열이 연속되는 구조일 가능성이 높은 것이다. 읽기때는 문제 없으나 새로운 항목을 추가해야 할 때는 문제가 될 수 있다. 배열이 커짐에 따라 뒤에 있는 배열이 확장을 막아서 메모리의 재할당·메모리 데이터 이동이 필요해 질수 있다. 배열에 항목을 추가할때 마다 매 번 발생할 수 도 있다. 가능하면 미리 넉넉하게 공간을 할당하는것을 고려하자. 동적으로 배열을 할당하면 Write때의 손실이 더 클수도 있다.
그리고 언어(컴파일러)에서 Auto Vectorization을 지원하는가에 따라 속도가 뻥튀기 해서 나오는 것을 볼 수 있다. Auto Vectorization 자체가 특수한 환경에서 발생하긴 하지만, 그것을 유도할 수 있다면 더욱 빠른 프로그램을 만들 수 있을것으로 보인다.

답글 남기기