분산 시스템이란
분산 시스템이란 공동의 목표를 달성하기 위해 여러 노드 또는 서버가 서로 연결된 소프트웨어 아키텍처다.
이 노드들은 네트워크를 통해 서로 통신하고 각자의 작업을 조정하여 통합되고 확장 가능한 컴퓨팅 환경을 제공한다.
Patterns of Distributed Systems (2023)
분산 시스템 내에서 작업 부하는 여러 서버에서 처리될 수 있어야 한다. 즉, 수평 확장을 통해서 요청을 동시 처리할 수 있어야 한다.
태초에는 단일 서버만이 존재했다.

태초에는 한 서버 내에서 비즈니스 로직과 DB 영역을 분리하였다. 서버 한대 내에서 모든 것을 처리했기 때문에, 서버 리소스를 전부 사용하면 그대로 뻗을 수 밖에 없다. 서버의 처리량을 높이는 방법은 서버의 스팩을 올리는 방법밖에 없다. (수직확장)
장애 대응에 있어서도 문제가 발생한다. 단일 서버이기 때문에 서버가 죽으면 서비스도 같이 죽는다. 웹 서버도 죽고 DB 서버도 죽는다.
stateful과 stateless의 분리
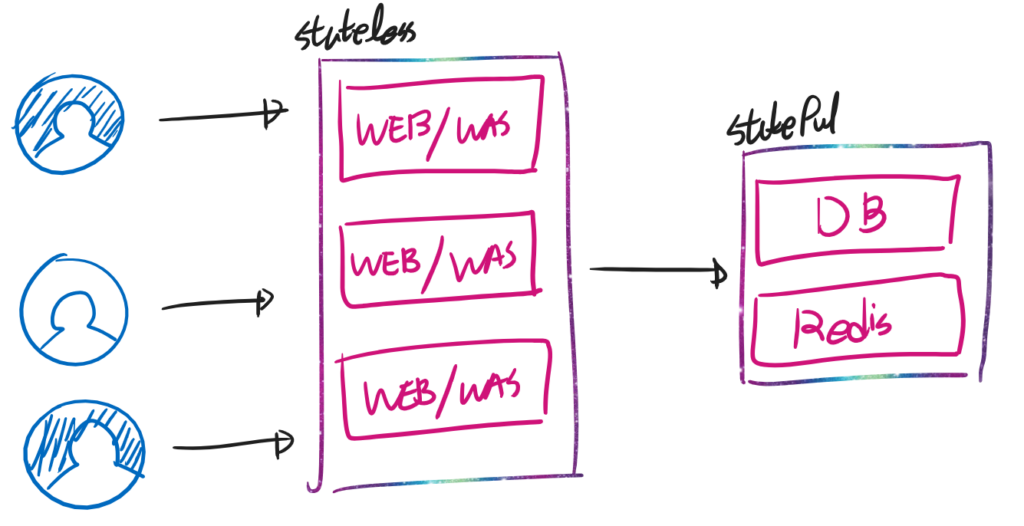
위의 예시에서 조금 더 발전된게 “stateless한 부분”과 “stateful한 부분”을 분리하는 것이다. stateless한 부분은 Pure Function으로 생각할 수 있다. 주변 환경에 영향을 받지 않으므로, 손쉽게 확장이 가능하다.
그러나 Stateful한 부분은 환경의 영향을 받는다. 여기에 그려진 DB/Redis는 데이터 영역에 해당한다. 정합성이 특히나 요구되는 부분이다. 그러므로 정교한 처리가 필요하다.
stateless란 “상태를 가지지 않는 것”을 의미한다. stateful은 반대로 “상태를 가지는 것”을 의미한다.
서버 영역에 있어서 stateless 하다는 것은 사용자 정보를 들고있을 필요가 없다는 것을 의미한다. stateful 하다는 것은 사용자의 정보를 계속 들고 있어야 한다는 뜻이다.
위의 그림에서 WEB/WAS 서버는 사용자의 정보를 가지지 않는다. (stateless) HTTP 요청이 오면 오는대로 처낸다. 세션 정보는 후방의 Redis 또는 별개의 sticky session 시스템이 처리할 것이다.
DB/Redis에서 사용자 정보를 실제로 가지게 된다.
그런 점에서 Stateless는 순수 함수에 빗댈 수 있다. f(x) = x + 1 이라는 함수는 주변 상태에 영향을 받지 않는다. 저 함수는 얼마든지 복제할 수 있다.
이 그림은 수평 확장이 용이한 stateless 부분에 분산 처리 구조를 적용한 모습이다. DB / Redis 영역은 그대로지만 이것만 해도 상당한 효과를 가진다. (개인적인 경험상 쿼리를 잘못짜지만 않았다면) WEB/WAS에 비해 DB의 CPU 사용량은 미미하다. 그러므로, 병목 현상을 가지는 WEB/WAS만 확장해도 처리량 확보에 큰 도움이 된다.
그러나 마찬가지로 한계점은 존재한다. 어쨋든 DB는 하나이다. DB쪽 사용률이 높아지면 전체 서비스가 느려진다. DB가 뻗으면 서비스도 죽는다.
데이터 영역도 나누다
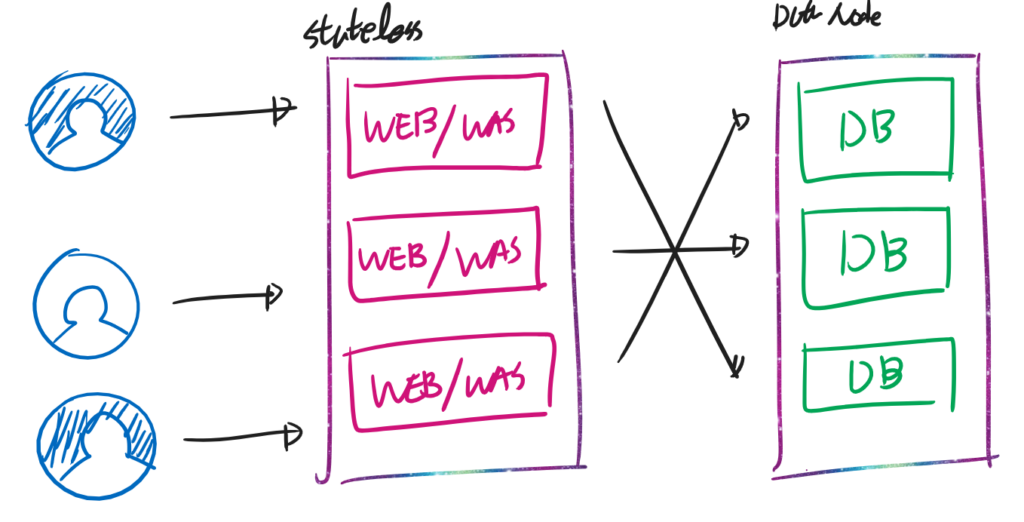
이제는 데이터 영역까지 분산 처리 구조를 가진다. Replication만 적용했는지, Data Partitioning까지 적용 했는지에 따라서 그 수준이 나뉜다. Replication 적용시 내장애성 및 읽기 성능의 향상을 꾀할 수 있다. 그러나 Write 성능 및 데이터 용량의 수평 확장은 어렵다.
Data Partitioning을 적용했다면 더 나은 내장애성 및 쓰기·읽기 성능 향상을 얻을 수 있다. 특히, 데이터가 각 노드에 나뉘어서 저장되므로 데이터 저장 용량 또한 수평 확장 가능하다. DB에서는 샤딩(Sharding) 이라는 용어를 사용한다.
데이터 정합성을 위한 기술
데이터를 분산 저장·처리 하기 위해서는 생각보다 많은 것을 고려 해야한다. 당장 단일 서버에 데이터를 저장할 때 부터 문제가 발생한다. 쿼리 여러개를 날렸는데, 쿼리가 중간에서 서버가 꺼지면 바로 문제가 발생한다. (All or Nothing이 불가능하다.) 최대한 한번에 몰아쓴다고 해도 원자성을 가지지는 못하다 (Atomic 하지는 못하다.)
Write-Ahead Log (WAL)
일반 DB에서 Binary Log라고 불리는 WAL이 정합성을 보장하기 위한 첫 단추이다. MySQL의 innobase에서는 Redo Log에 해당한다. WAL은 디스크 접근 중에 서버에 장애가 발생할 경우 생기는 문제를 막아준다.
예를 들어, A라는 사람이 B라는 사람에게 10만원을 송금을 한다고 생각해 보자. 아래 두 과정이 진행돼야 한다. (편의를 위하여 A는 10만원 이상 있다는 제약 조건과 Race Condition은 고려하지 않는다)
1) A 계좌에서 10만원을 뺀다
2) B 계좌에 10만원을 더한다어쨌든 해당 정보도 디스크 어딘가에 저장되어 있다. 위의 A, B 계좌에 대한 수정 점도 디스크에 저장돼야 한다. 이 행위는 A와 B 두 곳을 접근해야 한다. 즉, 두 개의 작업으로 구성되어 있기 때문에, 다시 말해서 원자적이지(atomic) 못하다
예시를 들어보자. 안타깝게도 1번이 수행되자 마자 서버가 꺼졌다. 그러면 [A 계좌에서 10만원이 빠진 상태] 까지만 저장될 것이다. 갑자기 10만원이 공중으로 떠버린 상태가 된다.
위 작업을 원자적으로 수행할 방법이 필요하다. 이때 Write-Ahead log가 사용될 수 있다. 실제 데이터 영역에 데이터를 쓰기 전에 Log에 해당 작업을 기록한다. 말 그대로 Write(쓰기)-Ahead(직전) Log 이다. 실제 데이터는 Write-Ahead Log에 의해서만 저장·수정된다. 위의 A → B 송금을 기준으로 생각해 보자.
0) 트랜잭션 시작 (트랜잭션 ID = ABCD 부여)
1) A 계좌에서 10만원을 뺀다 (쿼리 실행)
1-1) WAL에 [ABCD - A 계좌에서 10만원을 뺐다]는 정보 저장 (절대값)
2) B 계좌에 10만원을 더한다 (쿼리 실행)
2-1) WAL에 [ABCD - B 계좌에 10만원을 더한다]는 정보 저장 (절대값)
3) 트랜잭션 종료 (commit 실행)
3-1) WAL에 [ABCD와 관련된 정보 Flush]
3-2) commit 구문 종료WAL에 [ABCD 트랜잭션 성공] 이라는 데이터까지 저장돼야지 commit이 끝난다. commit을 실행하는데 10초가 걸렸다면, 그 중 1초는 WAL에 트랜잭션이 끝났다는 정보를 저장하는데 쓰였을 수도 있다 (농담).
실제 데이터에 반영하는 것은 별개의 쓰래드에서 담당한다. 별개의 반영 시스템이 WAL에 저장되어 있는 기록을 순서대로 실제 데이터에 반영한다. 만약 반영하다가 시스템이 꺼져도 괜찮다. 로그의 내용을 다시 반영하면 되기 때문이다.
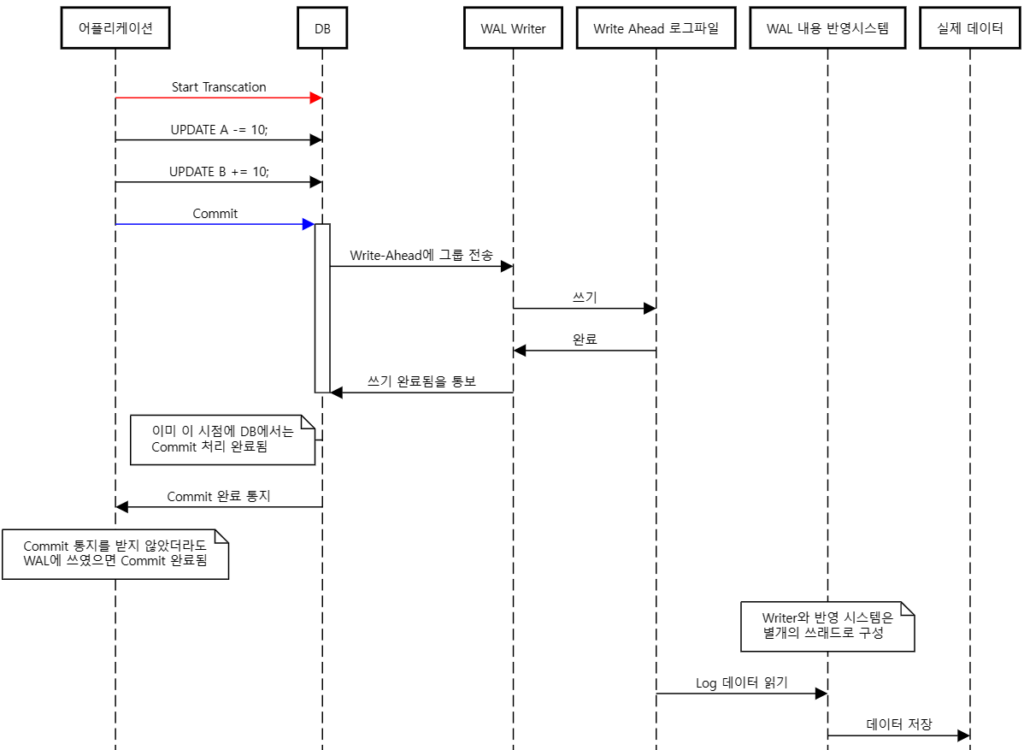
여기서 놓치면 안되는 것이 “WAL에 있는 데이터가 실제 Disk에 저장된 순간”이 commit이 끝난 시점이 아니다. “WAL에 데이터가 쓰여진 순간”이 commit이 완료된 지점이다.
MySQL(innobase) 에서는 Update와 같은 쿼리를 mini-transcation으로 더 잘게 쪼개서 내부적으로 동작한다. 예를 들어 “Update”문은 “데이터 수정”과 “Index Tree 수정” 으로 다시금 나뉘어진다.
innobase에서는 이 mini-transcation을 기반으로 Write-Ahead Log (ib_log)에 저장한다.
사용자의 트랜잭션이 끝나면 추가적인 mini-transaction(mtr)이 commit 된다. 그러면 트랜잭션을 시작했던 쿼리부터 방금 들어간 mtr까지 하나의 그룹이 된다. 그리고 해당 그룹이 WAL에 저장된다. (log_write_up_to) 즉, 하나의 트랜잭션 내에 있는 수정사항이 모두 그룹화 되어 저장된다.
innobase의 WAL은 Log는 논리 계층과 물리 계층이 나뉘어져 있다. 해당 데이터는 논리 계층에 의해 한 덩어리가 된다. 그리고 이것을 물리 계층에서 OS 페이지 단위인 512Byte로 쪼개서 직접 저장한다 (write through – durable => log_write_buf). 저장 할 때도 O_DIRECT등으로 OS 페이지 캐싱을 건너뛰기 때문에 장애 가능성을 낮춘다.
논리 계층은 하나의 덩어리이므로, 해당 덩어리가 “정상적으로 쓰였는지” 여부는 확인할 수 있다. (블록의 손상: 512Byte씩 끊어서 저장할 때 같이 저장되는 Checksum값 검증 / 쿼리의 마지막 까지 저장됐는지 여부: 2번째 문단의 추가 MTR가 발견 되는지 확인)
이를 통해서 “해당 그룹이 정상적으로 쓰였다”면 해당 트랜잭션은 “성공”으로 본다. 사용자가 commit을 실행했을 때 오류가 발생하더라도, 위의 mtr 까지만 Disk에 저장되면 트랜잭션은 성공한 셈이 된다.
When a user transaction commits, extra mtr is committed (related to undo log), and then user thread waits until the redo log is flushed up to the point, where log records of that mtr end.
MySQL 8.4.0 Source Code Documentation
During recovery only complete groups of log records are recovered and applied. Example given, if we had rotation in a tree, which resulted in changes to three nodes (pages), we have a guarantee, that either the whole rotation is recovered or nothing, so we will not end up with a tree that has incorrect structure.
https://dev.mysql.com/doc/dev/mysql-server/latest/PAGE_INNODB_REDO_LOG.html#subsect_redo_log_write_lsn
WAL에 들어간 정보는 과장을 더해서 수백회 실행될 수도 있다. WAL을 실제 데이터에 쓰는 중에 전원이 꺼지는 현상이 수차례 일어날 수 있기 때문이다. 그러므로 데이터는 멱등성을 가져야 한다. 그래서 WAL에 들어가는 데이터는 절대값이 들어간다.
만약, A가격 -= 10만원을 100회 반복하게 되면 A는 1,000만원이 사라진 것으로 보일것이다. 그러므로, WAL에는 A 가격은 5555만원임 와 같이 “그 자체로 상태를 표현할 수 있는” 값이 저장된다.
실제 MySQL의 binary log를 까보면 전부 절대값이 들어가 있는것을 볼 수 있다.
심지어 rand() 함수와 같이 비확정성 함수(쿼리)에서는 “이전값”과 “변경된 값”을 기록하여 수백번 반복이 가능하도록 보장한다.
여러 서버들 끼리의 정합성 보장
단일 서버 내에서 발생하는 데이터 정합성 문제는 해결됐다. 이제는 “분산 시스템” 답게 여러 서버들과 통신 해야한다. Active-Standby와 같이 한 곳에서만 Write를 하면 문제가 없다. 어짜피 모든 제어를 한 곳에서 하기 때문이다. 아래에서 부터는 Active-Active 상황만을 고려한다.
Leader and Follower
Active-Active인 상황에서 각각의 노드에서 동시에 동일한 데이터를 수정한다면 어떻게 될까? 아래의 그림에서 A계좌는 10만원인 상태와 30만원인 상태가 중첩되어 있다.
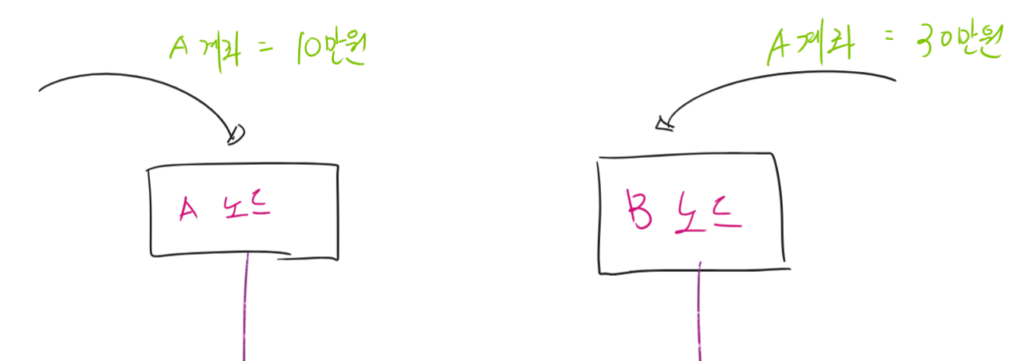
은행 지점으로 생각해 보자. 원래 A 계좌는 20만원이 있다. A노드 (=가상계좌 처리 서버)에서는 10만원을 인출해 갔다. B노드 (=송금 시스템)에서는 10만원을 넣으려 한다. 이 두가지가 동시에 온다면, 둘 중 하나는 덮어쓰기가 발생한다.
이 문제를 해결하기 위해 “Leader and Follower”라는 전략이 쓰인다. Leader는 결정권자고 Follower는 복종하는 노드이다. 즉, 위와 같은 데이터 경합 문제가 발생하면 Leader가 모두 결정한다.
대신, Leader는 데이터를 수정할 때 마다 각 Follower 에게 변경 사항을 전파해야 한다. (트래픽이 유난히 발생할 수 있다) 그러므로, 별도의 Relay 기능을 구현하지 않았다면 가장 많은 곳에 연결 가능한 노드가 리더가 되는 것이 좋다.
Version Control
“A 데이터와 B 데이터 중 무엇을 수용할 것인지”를 어떻게 결정할 것인가? 기본적으로는 Leader의 마음이다. 일반적으로는 Leader에 먼저 들어온 요청을 승인해 준다.
그러나 조금 강한 트랜잭션 보장을 생각하자. Write-After-Read 상황에서 “값의 버전”을 가지지 않으면 나중에 들어온 요청도 별개의 요청으로 보이게 된다.
A노드: 10만원 인출 요청
B노드: (더 일찍 요청을 했으나, 네트워크 지연으로 인해 1초 뒤) 10만원 입금 요청
-> Leader는 별개의 요청으로 보임한국-미국 사이의 RTT가 200ms가 걸린다. 필자의 경우, 한국-일본 도쿄 연결시 [한국-미국-유럽-싱가폴-일본]을 거쳐서 500ms가 걸린적도 있다. 여기에서 패킷 손실까지 생각한다면 2~5초 까지도 지연이 생길 수 있다. [특정 데이터 수정 후 n초간 요청은 전부 금지] 처럼 시간으로 밀고 나가면 서버의 처리량에 문제가 생긴다. 특히 패킷 손실이 큰 경우에는 5초의 시간을 주고도 충돌이 발생할 수 있다.
이 문제는 각 데이터에 버전 정보를 주면 해결된다. 대신, 서버는 이제 버전 정보도 같이 저장해야 한다.
A노드: (계좌 A: 버전 1) 10만원 인출 요청
(계좌 A: 버전 2로 수정)
B노드: (계좌 A: 버전 1) 10만원 입금 요청
-> 버전 2가 최신 상태임. B노드의 요청은 거절값 지정에 대한 제약이 크지 않을 경우 버전 컨트롤은 굳이 필요 없을수도 있다.
다만, 이 경우 Leader는 “제약 조건” 관리의 의무를 가져야 한다.
예) 최초 A의 계좌는 10만원
A노드: 10만원 인출 요청
B노드: 10만원 인출 요청 <- 제약에 의해 거부 해야함
Leader를 동시성 처리를 위해 존재하는 단일 쓰레드라고 생각하면 편하다. 다만에, 트랜잭션중 값 변경에 대응하기 위해서는 결국 MVCC까지 가야 할 것이다.
Leader Node 다운
Leader가 다운되면 Follower들은 Write 요청을 할 수 없다. 그러므로, 클러스터 내에서 주기적으로 서버가 살아있는지 확인해야 한다.
주기적으로 서버가 살아 있는지를 확인하는 방법을 Heart Beat라고 한다. 우리는 가능한 짧은 시간마다 Heart Beat를 이용하여 Leader가 살아있는지 확인해야 한다. 방법은 다양하다. 서버가 죽었는지 살았는지를 확인하는것 뿐이므로, HTTP 요청을 주기적으로 때리거나 TCP에 Ping-Pong 기능만 추가해도 된다.
Heart-Beat을 이용해서 Leader가 다운됐다는 것을 확인했다 치자. Leader 다운 시에는 두가지를 고려해야 한다: 1) 부분 연결 문제, 2) Leader에서만 승인된 데이터.
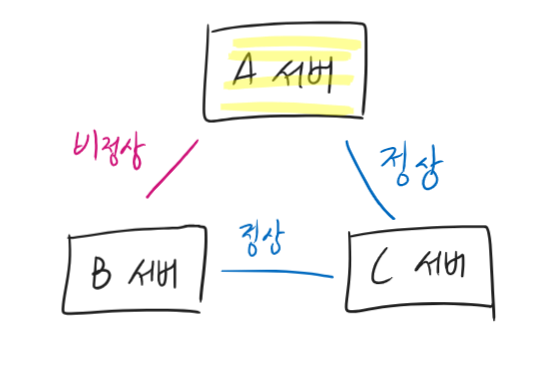
일단 “Leader와 연결이 되지 않으면” B는 무조건 “Leader 재선출” 과정을 실행한다. 그러면 옆에 있는 서버들이 찬/반 투표를 한다. Leader와 연결되지 않는 노드들만 Leader 선출에 찬성한다. 그러므로, Leader와 연결되는 노드가 과반수 이상이라면 그대로 있어도 된다. 오히려 내가 Leader와 연결되지 않는 소수이기 때문이다. (더 많은 노드와 연결되는 노드가 있다면 Leader로 임명해도 무방하다)
Majority Quorum (과반 이상의 투표자 / 정족수)
이번에는 A서버는 아무 곳에도 연결하지 못한다. Heart-Beat로 본인이 장애임을 인식했다면 Leader를 내려놓았을 것이므로 문제가 없다. 문제는 Heart-Beat가 실행되기 이전이다. 자신이 아직 Leader로 판단하여 신나게 요청을 받았을 것이다.
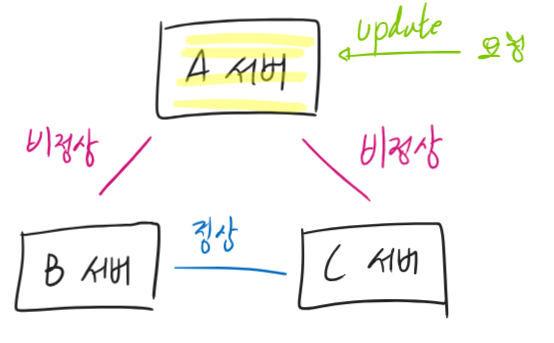
그렇다면 이렇게 받은 요청은 어떻게 될까? 서버 내 WAL에 기록하자 마자 트랜잭션을 승인해 주었다면 데이터 부정합이 발생한다.
이 문제를 해결하기 위하여 “Leader는 독단적으로 승인할 수 없다”라는 규칙을 추가해야 한다. Leader를 그룹화 하면 된다. 어떤 요청이 왔을 때, 3개의 서버라면 과반인 2개의 서버가 승인해 줘야 한다는 규칙을 추가한다.
Leader 본인도 투표자이므로 정족수 2중 1개는 동의된 셈이다. 다시 말해서, 1개의 서버에만 동의를 받으면 된다. 만약 5개 서버라면 3개의 과반 승인이 필요하다. 그 중, 자신을 제외한 2개의 서버에서만 승인 받으면 된다.
“승인을 받았다”는 것은 각 서버의 로그에 기록까지 완료한 상태이다. 만약 Leader가 죽었다면 남은 Follower 끼리 새로운 Leader 선출을 위한 투표가 진행될 것이다. Major Quorum에 해당하는 노드들이 승인한 로그를 가지고 있다. 이 로그들은 새로운 Leader가 선출될 때 Leader에게 보내지고 반영된다. 이를 통하여 A 서버가 수행했던 마지막 작업 정보를 나머지 노드 들에서 알아차릴 수 있다.
Leader and Follower를 위한 추가 요소들
Leader and Follower는 위의 개념이 주요 컨셉이다. 그러나 저것 만으로는 데이터의 정합성을 보장할 수 없다.
기존 Leader (= A)에 장애가 발생하여 투표를 진행했다. 그래서 새 Leader(= B)가 뽑혔다. 이때, 만년 Follower였던 C에 장애가 발생했다. 기존 Leader(=A)와 새 Leader사이의 연결이 복구되자 마자 투표가 실시됐다.
이때, A와 B중 어느 데이터가 더 최신인지 판단 할 수 없다. 우리는 상황을 봐서 B가 최신인지 알지만, B도 몇 초간 오프라인 상태였다. 그러므로 A가 조금 더 최신이다! 라고 생각할 수 도 있다. 이 문제를 해결하기 위해 Generation Clock이 필요하다.
또한, 5개의 node에서 요청을 처리하려면 과반 정족수 문제로 인하여 본인을 제외한 2개의 노드에서의 승인이 필요하다. 이때 첫번째 Follower는 승인을 해 줬으나, 두번째 Follower에 투표를 요청하려는 순간 네트워크가 끊기면 어떻게 되는가? 첫번째 Follower에 별다른 장치가 없으므로 데이터가 이미 WAL에 쓰였을 것이다.
다시 말해서, 노드 수가 5개 이상이 되는 순간 과반 투표의 원자성이 사라진다. 이 문제를 해결하기 위해 high-water mark가 필요하다. 정족 투표 결과는 또다시 별개로 저장한다. high-water mark를 통해 과반 이상의 동의를 받았다고 확정이 나면 그제서야 데이터를 적용한다.
이러한 심화적인 요소들은 다음 글에서 이어서 설명하도록 한다.

답글 남기기