유챗에서 작동하는 간단한 봇을 만드려는 중에, 관련된 자료가 검색해도 보이지 안길레 적어본다. 어디까지나 내가 코드를 분석하면서 찾은것을 기반으로 작성한 글이기에 부정확한 내용이 있을 수도 있다.
우선 유챗의 통신 내용을 들여다보면 아래와 같이 나온다:
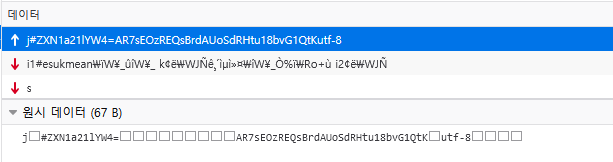
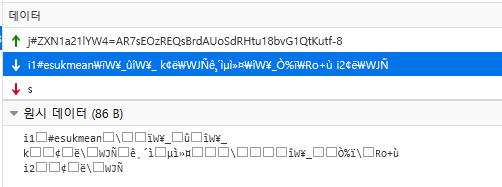
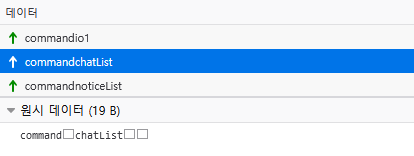
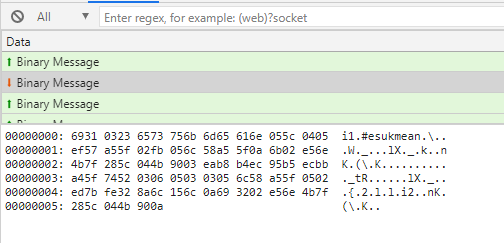
모든 통신은 웹소켓을 기반으로 동작하고 있음을 볼 수 있다. 특히 웹소켓중 바이너리 타입으로 데이터를 송수신 함을 볼 수 있다. 하나의 웹소켓 패킷(바이너리 타입 메세지) 안에서는 \n을 기준으로 여러개의 메세지를 담을 수 있다. 메세지는 중간에 끊어짐이 없다. 각 줄의 메세지는 다시 \x02, \x03, \x04, \x05, \x06, \x07 등으로 내용 구분된다.
다시 말하자면, 우선 바이너리 타입의 웹소켓 패킷으로 메세지의 덩어리가 온다. 들어온 메세지 덩어리는 우선 \n 단위로 나눠진다. 그렇게 나눠진 한줄 한줄 나눠진 메세지는 다시 \x02~\x07을 구분자로 해서 내용이 나뉘어진다.
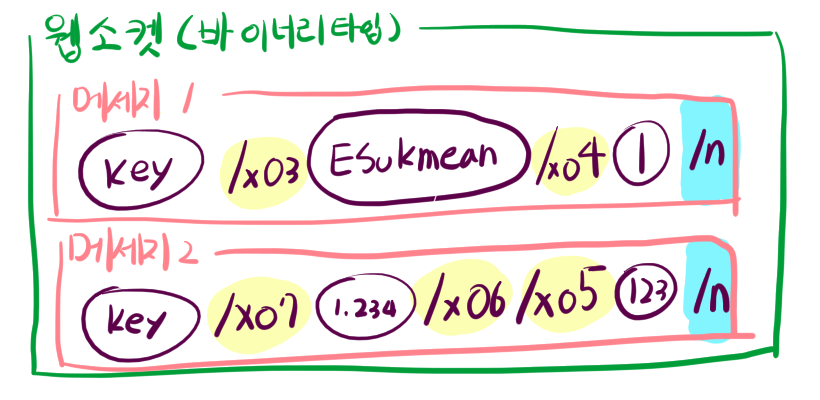
각 메세지는 (노란색) 구분자에 의해 내용의 타입이 정해진다.
맨 앞에는 메세지의 타입(기능)을 구분해 놓은것 인 것 같고, 나머지는 자신의 데이터 맨 앞에 있는 구분자에 의해 해당 내용(데이터)의 타입이 정해지는 것 같았다. 메세지1에 \x03 ESukmean 이라고 있으면, 이는 문자열 “ESukmean”임을 뜻한다. \x04 1이 있으면 이는 true를 의미한다.
내용들이 구분자로 (\x03 ~ \x07, \n등) 쪼개지기에 프로그램이 구분자와 일반 데이터를 구분하는것이 매우 중요하다. 누군가의 채팅 내용에 \n이 있었는데, 그것을 메세지의 분리로 인식하면 프로그램의 버그가 발생할 것이다. 이를 방지하기 위해 혹시라도 구분자에 해당되는 데이터가 들어온다면 그 앞에 \을 붙여서 escape하는 것 같았다. 예를 들어, 채팅 내용이 “가나다라 \n 아자차카” 라면, 우리가 받는 메세지는 “가나다라\\\n아자차카”가 되는것이다. “1234 \x06 5678″ 이라는 데이터는 “1234 \\\x06 5678″로 들어올 것이다.
UChat.js를 보면 아래와 같은 구분자 타입이 존재함을 알 수 있다.
- \x02 -> 바이너리 데이터
- \x03 -> 문자열 데이터
- \x04 -> boolean 데이터 (이때 boolean은 ascii 48(‘0’), 49(‘1’)로 true false가 구별된다)
- \x05 -> 숫자 (정수) (코드를 보니까 가변 길이의 바이트같다. 몇 바이트의 데이터로 들어오는지 확인해야 한다)
- \x06 -> undefined (Python의 None, Java의 Null 등에 대응되는 듯 하다.)
- \x07 -> float (특이하게 문자열로 전송된다. 1.234를 보낸다고 하면 float이나 double이 아닌 “1.234” 문자열이 전송되는 방식)
- \n -> 메세지를 구분한다.
- \\ -> escape code로 쓰인다.
// uchat.js
while ( index < last ) {
var str = data.charAt(index);
switch(str) {
case '\x02': case '\x03': case '\x04': case '\x05': case '\x06': case '\x07':
if ( mode == '\x02' ) {
result.push(buffer.join(''));
} else if ( mode == '\x03' ) {
result.push(buffer.join(''));
} else if ( mode == '\x04' ) {
if ( buffer.join('') == '1' )
result.push(true);
else
result.push(false);
} else if ( mode == '\x05' ) {
result.push(b2n(buffer.join('')));
} else if ( mode == '\x06' ) {
result.push(undefined);
} else if ( mode == '\x07' ) {
result.push(Number(buffer.join('')));
}
buffer.length = 0;
mode = str;
break;
case '\\':
index++;
if ( index < last ) {
if ( escape.indexOf( data.charAt(index) ) == -1 && data.charAt( index ) != '\\' )
buffer.push( str );
buffer.push( data.charAt( index ) );
}
break;
default:
buffer.push(str);
}
index++;
}//uchat.js
case 'string':
if(i)
result.push('\x03')
result.push(protocol_value_escape( data[i] ) )
break;
case 'boolean':
if(i)
result.push('\x04')
if(data[i])
result.push('1')
else
result.push('0')
break;
case 'number':
if(data[i] % 1 === 0 && data[i] >= 0 ) {
if(i)
result.push('\x05');
result.push( protocol_value_escape( n2b(data[i]) ) );
} else {
if(i)
result.push('\x07');
result.push( protocol_value_escape( data[i].toString() ) );
}
break;
case 'undefined':
if(i)
result.push('\x06')
break;\x00, \x01이 정의되어 있지 않다. 미래에 쓰일 수 도 있을것 같다. (일종의 reserved 형태로 지정한 것 같다) 마찬가지로 byte 7 이후도 미래에서는 구분자로 쓰일 수 있다. 2~7 사이가 아닌 바이트로 구분자 역할을 하는것 같다면… uchat.js를 파 보는것이 좋을듯 하다.
내가 위에서는 메세지의 맨 앞을 key로써 별도의 데이터로 구분했었다. uchat.js를 보니까 그냥 문자열 형태로 깡그리 처리 하는 것 같다. 이건 개발자가 적절히 처리하면 될 것 같다.
단, key의 바이트 길이에는 제한이 없다는것을 유의해야 한다. 처음에는 key가 1글자 (k, j등)로만 와서 1byte char로 생각하고 코드를 만들었다. 그런데 나중에 보니 2byte (i1, i2등) 데이터도 있음을 확인했다. uchat.js에도 별도의 바이트 길이가 정해져 있는것 같진 않으니… 안전하게 String 형태로 가는게 좋을 듯 하다.
Rust로 구현한 protocol 부분은 다음과 같다: https://github.com/ESukmean/uchat2-bot/blob/main/src/uchat/protocol.rs 구현하면서 주의해야 했던 점은 escape 부분과 가변 바이트의 정수 타입이었다. 그 외는 적절히 위의 spec에 따라서 구현하면 될 것 같다.
유챗은 웹소켓으로 들어오는 메세지 자체가 하나의 완전한 메세지로 들어온다. 중간에 끊어짐이 없기 때문에 (끊어졌더라도 WS Protocol단에서 모두 조립후 완전한 메세지가 되어야 던저주기에) “일반 소켓 프로그래밍처럼 데이터가 중간에 끊어진 채로 들어오면 어떻게 하지?” 와 같은 걱정은 할 필요 없다. (WS Protocol까지 직접 구현한다면… 고려해야한다)
일단은 이렇게 제일 하단의 프로토콜 분석 끄읏.
답글 남기기