abbyy FineReader 16로 PNG로 되어 있는 파일을 OCR로 인식후 pdf로 저장할 때 다음과 같은 문제가 발생했다
- 변환된 pdf내에 페이지 크기가 전부 다름
- 일부 페이지의 내용이 지나치게 깨짐. (글자의 해상도가 떨어진 느낌)
결과적으로 말하면.. FineReader에서 이미지를 로딩할 때 dpi(해상도)를 자동 판별한다. 이미지들의 가로x세로 픽셀 수가 같더라도 DPI가 제대로 인식 안될때가 있다. 필자는 수백장 짜리 보고서를 동일한 해상도의 png 파일로 캡쳐해서 OCR로 돌렸는데, 80 DPI 부터 490 DPI까지 제각기 다른 DPI가 나왔다.
이미지 DPI 계산
이럴때는 DPI를 수동으로 설정해 주면 된다. 우선 DPI를 산출하는 공식을 보자. (https://support.abbyy.com/hc/en-us/articles/360017733859-How-FineReader-Engine-calculates-resolution-of-the-input-image)
How FineReader Engine calculates resolution of the input image
- EXIF is present:
Resolution is calculated by the formula:max(96, RoundTo(max(width/8, height/12),10)).- EXIF is absent, and an image is anisotropic:
- One of the dimensions is 50dpi or less – resolution is calculated by formula from p.1;
- The degree of anisotropy is below 10% – resolution is equated with the biggest one;
- The degree of anisotropy is above 10% – an image is resampled up to the biggest resolution.
- EXIF is absent, and an image is isotropic:
- Resolution is below 50 dpi – resolution is calculated by formula from p.1;
- Resolution is below 140 dpi, and the formula from p.1 gives a bigger one – the image resolution is left intake, but internally Engine works with resolution calculated by the formula from p.1;
- Resolution is above 140 dpi – resolution is equated with it.
아쉽게도 PNG에는 EXIF가 없다. 그러면서 내부적으로 이상한 로직으로 인해 DPI 판단에 착오가 생기는것으로 보인다. 어쨋든, 동일한 조건에서 만든 png의 경우 1번 로직으로 계산해 보면 된다.
- (
가로px / 8)과 (세로px / 12) 중에서 더 큰 값을 선택 - 위에서 나온 “
더 큰 값“을 10의 자리로 반올림 실시 - 반올림 된 숫자가 96보다 작다면 96을 사용함
만약 가로x세로의 픽셀이 2488×3508이면 (2488 / 8 = 311), (3508 / 12 = 292) 중에서 더 큰 311을 선택한다. 이 수를 10의 자리로 반올림 하여 310을 선택한다. 즉, 우리는 310을 DPI로 설정할 예정이다.
이미지 사전처리 해제
abbyy OCR 편집기에서 이미지를 로딩하면 자동으로 이미지를 사전 처리한다. 이 과정에서 이미지의 해상도가 프로그램이 잘못 추론한 해상도로 바뀐다. 그러므로, 이미지 사전 처리 기능을 해제하고 수동으로 DPI를 설정해야 한다.
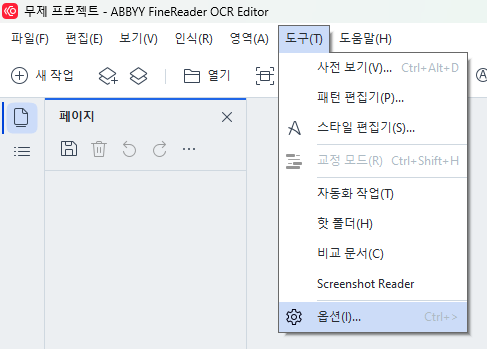
Ctrl+>) 에 들어간다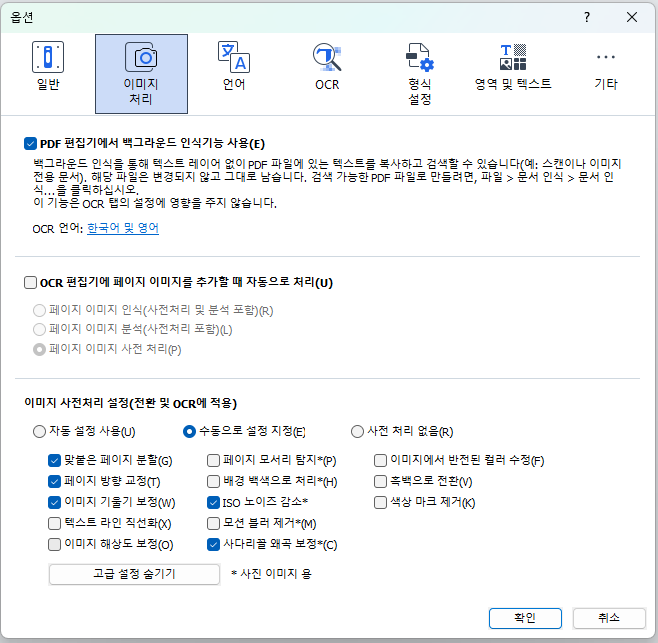
“이미지 사전 처리 설정”에 “수동으로 설정 지정”을 선택한다. 여기서 “이미지 해상도 보정”을 체크 해제한다.
중요한건 우리가 직접 DPI를 설정할 때 까지 프로그램이 개입하지 않도록 하는 것이다. 그러므로, 이미지 추가시 자동으로 처리하는 옵션을 끈다. 또한, 이미지 사전 처리시에 해상도를 보정하는 기능도 해제한다.
설정이 완료된 후, 이미지를 전부 로딩한다. 그리고 “이미지 편집” 에 들어간다.

그리고, 오른쪽에 나온 메뉴들 중 “해상도” 탭에 들어간다. 해상도 “기타”를 선택하고 위에서 계산했던 DPI 값을 입력한다. 적용을 위해서 선택(S)에 “모든 페이지”를 선택한 뒤, 적용 버튼을 누른다. 필자의 경우에는 310로 입력했다.
310 은 아까 전에 DPI 계산에 의해 나온 값이다. 이미지의 가로·세로 해상도/8 를 해서 더 큰 수이다.
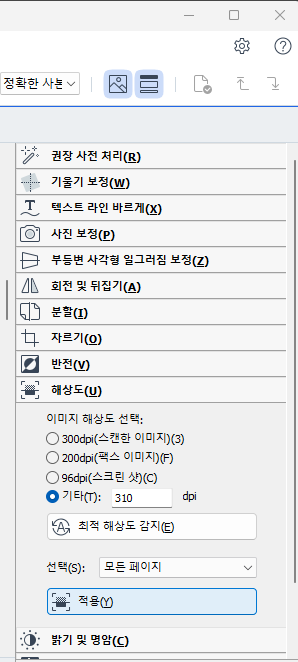
처리가 완료된 후에는 이미지 편집기를 종료하여 빠저나온다.
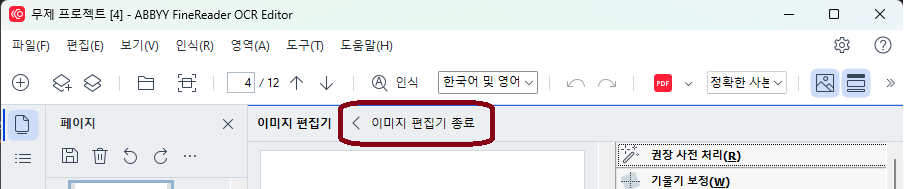
해상도 설정이 완료 됐으므로, 이미지 사전 처리를 실시한다. “모든 이미지 사전 처리(R)”을 누르면 된다.
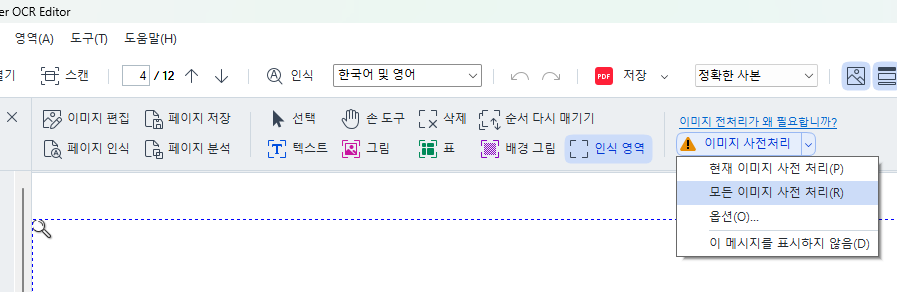
이미지 인식(OCR) 수행
이미지 사전처리 이후, 수동으로 “모든 페이지 분석” 및 “모든 페이지 인식”을 눌려서 OCR을 실시한다.
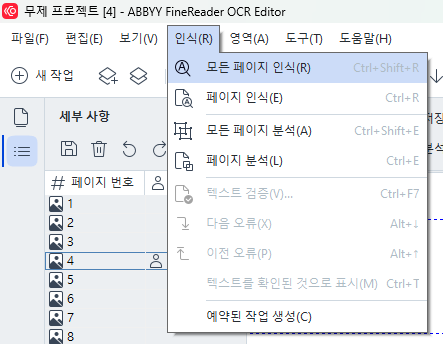
끝맺음
위의 방법으로 abbyy FineReader에서 OCR 인식시에 각 페이지의 크기가 다르거나, 일부 페이지가 심하게 깨져보이는 문제를 해결할 수 있었다.
필자의 경우에는 png 파일을 바로 OCR로 돌려서 발생한 문제 같은데, 스캐너로 만든 JPEG 등의 이미지는 EXIF덕에 문제 없을 것 같다. 화면에서 직접 캡쳐한 이미지를 쓸 때만 사용하자.
한편, 이와 관련된 지원 포럼 글이나 설명이 전무해서 삽질을 많이 했다. 이미지 사전처리 설정을 꺼라는 말 까지는 봤는데, 더욱 중요한 “해상도를 직접 설정”해야 한다는 파트가 없어서 삽질을 했다. 해상도만 잘 지정하면 아무 문제가 없으며, Acrobat Pro 보다도 훨씬 나은 것 같다.

답글 남기기